Blogサイト構築で理解するXMLデータベース 第2回
※日経Linuxにて掲載。この記事掲載については編集部に了承。


第2回 XMLデータ構造の決定とXMLデータ操作プログラムの作成
日本ユニテック 吉田 晃伸
前回は,柔軟なデータ形式に対応できるXML(eXtensible MarkupLanguage)というマークアップ言語と,XMLデータをそのまま格納できるXMLデータベースの魅力について紹介しました。XMLデータベースの実際の例として,三井物産が販売する有償XMLデータベース製品「NeoCore XMS」の無償版に当たる「Xpriori」というソフトウエアを取り上げ,その概要とインストールについても解説しました。
今回からは,いよいよ本連載の目的であるBlogサイト構築に取り掛かります。具体的なシステム構築を通じて,XMLデータやXMLデータベースの使い方に触れていきましょう。
目標とするBlogサイトの構成
最初に,構築するBlogサイトの構成を考えます。まず,Blogサイトですからサイト訪問者向けのWebページを用意する必要があります。いくつかの方式がありますが,ここでは,タイトル一覧ページを用意し,そこから詳細ページにリンクする形でサイト訪問者向けページを用意することにします。さらに,記事を追加したり修正したりする管理用のWebページも用意します。サイトの全体構成は図1のようになります。BlogサイトのデータはすべてXMLデータとして表現します。XMLデータはXprioriに格納し,CGIプログラム経由で入出力することにします。
図1:本記事で構築するBlogサイトの全体構成
サイト訪問者向けのWebページと、管理用のWebページの2つに分けています。
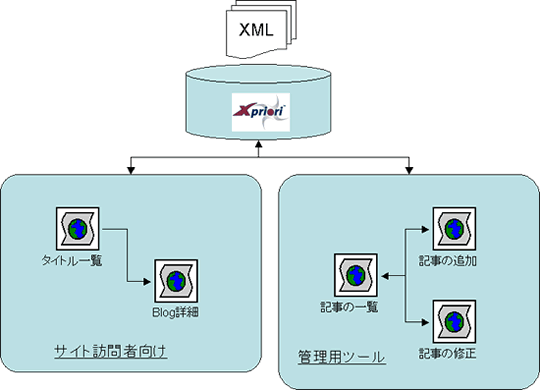
今回の記事では,(1)XMLデータの構造を決める,(2)Xprioriにデータを格納する,(3)XMLデータを検索してそれを表示する,という3つの作業を実施します。
記事データのXML構造の決定
Blogサイトに掲載する記事データのXML構造を考えてみましょう。第1回目の記事でも紹介したように,XMLではデータの項目とそれらの関係性を「タグ」を使って表現します。まずBlogサイトで必要となるデータ項目を洗い出し,その関係性を定義することから始めましょう。
記事関連では,「記事のタイトル」,「記事の本文」,「記事の作成年月日」のデータが必要です。また,Blogでは,ある記事に対する反応(コメント)を「トラックバック」として公開するのが一般的です。このトラックバックを取得するためのURLデータ(トラックバックURL)も保持することにします。さらに記事は,複数本を持てるようにする必要があります。それぞれのデータ項目にXMLのタグ名をつけましょう。タグ名とデータ項目の関係性を表1に示します。
表1:Blog 記事のXMLデータにおけるタグ名とデータ項目の関係
| タグ名 | データ項目名 |
|---|---|
| title | 記事のタイトル |
| contents | 記事の本文 |
| date | 記事の作成年月日 |
| trackback | トラックバックURL |
これらのタグの中に,実際のデータ(文字列)を入れます。次に,これらのデータ項目の関係性やそのほかに必要なデータ項目を定義します。
サイト全体のXMLデータを「blog」要素で表します。投稿記事の集合を「entries」要素で表すことにしましょう。また,一つひとつの記事を「entry」要素で表します。
このようにしてデータ項目とその関係性を考えた結果,XMLの構造は図2のようになります。実際のXMLデータを図3に示します。XMLデータは後からでも自由に拡張が可能ですので,まずは必要最小限のデータ項目を規定するにとどめています。
図2:Blogサイトで使用するXMLデータの構造
各記事をentry要素として管理します。記事内にはtitle,contents,date,trackbackの要素があります。
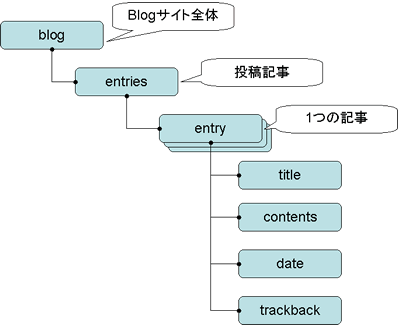
図3:Blog記事データのサンプル
Blog記事は,このようなXMLデータとして格納されます。この例では3つの記事が格納されています。
<?xml version="1.0" encoding="UTF-8"?>
<blog>
<entries>
<entry>
<title>1リーグ制への移行に関して。。</title>
<contents>絶対反対です!(-_-;)</contents>
<trackback>http://www.geocities.jp/bibun_houteishiki/nabe/</trackback>
<date>2004-08-06</date>
</entry>
<entry>
<title>今日も負けた。。。</title>
<contents>4連敗です。。。ちょっと前に6連勝したのに台無し。今年は異常に巨人に弱いのが気になる
</contents>
<trackback></trackback>
<date>2004-08-04</date>
</entry>
<entry>
<title>アニキ!</title>
<contents>ついに日本記録達成ですね!おめでとうございます。次は世界を目指して・・・</contents>
<trackback></trackback>
<date>2004-08-01</date>
</entry>
</entries>
</blog>
図3に示したXMLデータは,第1回目の記事で紹介したXprioriの管理ツールを使ってデータベースに格納しておいてください。
記事タイトルの一覧を表示する
続いて,XMLデータベースに格納したXMLデータを処理するCGIプログラムを作成します。
まず手始めに,記事のタイトル一覧を表示するプログラムを作成しましょう。これはXMLデータから記事のタイトル(title要素)だけを取り出してブラウザに表示するプログラムです。前回の記事で紹介したプログラムを変更して,記事のタイトルを抜き出すプログラムにします(図4)。
図4:記事タイトルを抜き出すPerlプログラムの例
XMLデータのtitle要素を抜き出すよう指示しています。第1回で紹介したXMLデータベースに問い合わせを出すプログラムを改良したものです。
#!/usr/bin/perl
use NeoProxy; # HTTP API Perl implementation
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
$USERNAME = "Administrator";
$PASSWORD = "unitec";
$result = $my_proxy->login($USERNAME, $PASSWORD);
#Title要素を検索する
$result = $my_proxy->queryXML("/ND/blog/entries/entry/title");
print $result;
$result = $my_proxy->logout();
変更したのはリスト中の太字の部分です。前回紹介したように,「queryXML」メソッドの引数として検索条件を記述します。この検索条件部分を記事のタイトルを取り出すように変更します。検索条件は「XQuery」と呼ばれるXMLの検索言語を使用して記述します。
PostgreSQLやMySQLなどに代表されるRDBMSでは「SQL」文を使ってデータベースの内容を検索します。同様にXMLの場合は,XQueryと呼ばれるXML専用の検索言語を使ってデータを検索します。XQueryは,Xpriori専用の検索言語ではありません。「W3C」(World Wide Web Consortium *1)が標準化するXMLデータ向けの検索言語です。他のXMLデータベースも多くの場合,XQueryを検索に利用できます*2。
*1 W3C(http://www.w3c.org/)は、インターネットで利用される様々な技術の標準化団体です。同団体が策定した代表的な規格にはHTMLやXML、SOAP(Simple Object Access Protocol)などがあります。
*2 XQueryはまだ新しい規格のため、未対応のXMLデータベースもあります。
ここでSQL文の基本的な書き方を思い出してください。SQL文ではSELECT文を使用して,検索の対象となるテーブル内のフィールドを指定します。次に,FROM句を使用してテーブルを指定します。つまりSELECT文とFROM句を使用して,検索対象となるデータ項目を絞り込んでいることになります。今回のBlogサイトをRDBMSで構築する場合,タイトル一覧を取得するには次のようなSQL文を使います。これで,entryテーブル内のtitleフィールドのデータを一覧出力できます。
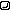 このマークで改行
このマークで改行
XQueryも検索言語ですので似たような記述になります。書き方は異なりますが,検索対象となるデータ構造やデータ項目を絞り込んでいく点は同じです。ただしXMLの場合,テーブルやフィールドといった概念を持ちません。検索対象を絞り込むためには,XMLのデータ項目名(タグ名)とその関係性(階層構造)を指定します。先ほどのスクリプトでは「/ND/blog/entries/entry/title」という記述で検索対象を絞り込んでいます。
これで分かる通り,XQuery文では,XMLのタグ名を「/」で区切って並べます。XMLデータの階層構造を「/」区切りで指定しているのです。左側ほど上位の要素であることを示します。つまり,このXQuery文は「ND要素の下のblog要素の下のentries要素の下のentry要素の下のtitle要素」の一覧を示すことが分かります(図5)。なお,なぜND要素から指定しているかについては,「XprioriはND要素の子要素としてデータを格納」を参照してください。
図5:問い合わせ言語によるデータの特定
RDBMSではSQLを、XMLデータベースではXQueryを使って検索対象を特定します。XQueryでは、XMLデータの階層構造を使ってデータを特定します。
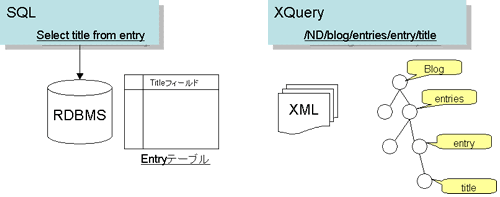
このようにXQueryでは,XMLデータベース内のデータを,データの階層構造を使って指定できます。XMLデータベースは,与えられたXQueryに対応したデータを結果として返送するよう動作します。
ただし,Xprioriの問い合わせ処理では1点注意すべき事柄があります。それは,XQueryで記述された構造が,検索対象となるXMLデータに存在しない構造であったとしてもエラーにならず*3,単に「該当なし」という検索結果が返ってくることです。
*3 もちろん、検索文字の先頭を「/」で始めなかった、などXQueryの構文自体が間違っていればそれはエラーになります。
RDBMSの場合,データベース内に存在しないテーブル名やフィールド名をSQL文で指定すると,その時点でエラーが返されます。RDBMSの場合,テーブル名やフィールド名が固定されているため,検索で異なる名称が指定されればエラーと判断できるからです。
しかし,Xprioriのようなデータ構造を定義しないタイプのXMLデータベースでは,検索で指定した構造が現在たまたま存在しなかったとしても,それがエラーかどうかを判別できません。そのため,対象となるXMLデータに存在しない構造を検索条件に指定してもエラーにならないのです。
図4のサンプル・スクリプトを,コマンド・ラインで実行した結果を図6に挙げました。title要素が結果として表示されていますので,タイトル一覧が正しく検索・取得できたことが分かります。実行結果を見て分かる通り,検索結果はXprioriからXMLデータとして返ってきます。
図6:サンプル・プログラムでtitle要素を抜き出した様子
結果がXprioriからXML形式で出力されているのが分かります。
$perl getTitle.pl
<?xml version="1.0" encoding="utf-8" ?> <Query-Results> <title>1リーグ制への移行に関して。。</title> <title>今日も負けた。。。</title> <title>アニキ!</title> </Query-Results>
DOMを使ってXMLデータの扱いを容易に
XQueryでの検索結果がXMLで返ってきますので,それを扱うPerlのプログラムも,XMLデータを処理できなければなりません。最終的にWebブラウザに表示させることを考えると,XMLデータをそのまま出力するのではなく,結果のXMLデータから必要な文字列(title要素の文字列)だけを抜き出して出力したいところです。
Perlは文字列処理が得意なプログラミング言語です。そのため返送されるXMLデータの構造が分かれば,文字列処理だけでもtitle要素の内容を抜き出せます。しかし,XMLデータを処理するモジュールを利用すれば,より簡単にプログラムを記述できます。
XMLデータを処理するためのPerlモジュールにはいくつかあります*4。本連載では,汎用性を考えて,DOM(Document Object Model)と呼ばれる標準API(Application Programming Interface)を用いる「XML::DOM」モジュールを利用することにします。
*4 本記事で紹介したXML::DOMモジュールのほかに、SAXやXML::Parser、XML::Groveといったモジュールがあります。Perl関連プログラムを配布するCPAN(http://www.cpan.org/)で、「XML」をキーワードに検索すると多数のモジュールがみつかります。
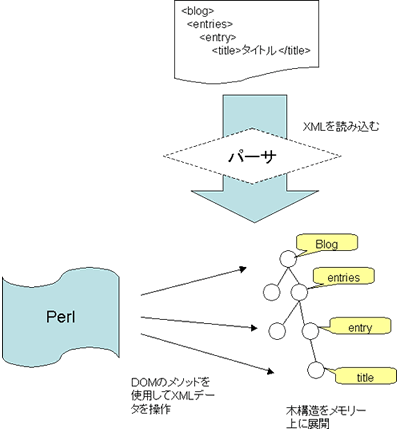
DOMは,XMLデータ操作用に規定されたAPIです。XQueryと同様にW3Cが標準化しています。DOMを使った処理は基本的に,メモリー上に木構造として展開したXMLデータに対して実施されます。木構造の内容を参照したり,木構造を変更したりするメソッドが多数定められており,それらのメソッドを Perlプログラムから利用してXMLデータを操作します。XMLデータを木構造に展開するのは「パーサー」と呼ばれるプログラムの仕事です(図7)。
図7:DOMを使ったXMLデータ操作の流れ
パーサーでXMLデータを木構造に展開し、その木構造を操作するメソッドを使ってXMLデータを操作します。
Perlプログラムで,XML::DOMモジュールを使用するには,Perlプログラムの先頭に下記の1文を記述します。
次にDOMを通じてXMLデータを扱えるように,パーサーを呼び出してXMLデータを読み込ませます。これには例えば,図8のようなコードを記述します。これでXMLデータがプログラムから扱えるように木構造に展開されます。
図8:パーサーの呼び出し例
XMLデータを木構造に展開するには、このようなPerlプログラムを記述します。
my $doc =$parser->parse($result);
木構造に展開されたXMLデータの特定の要素を取り出すには,「getElementsByTagName」というメソッドを使用します。このメソッドは,必要とする要素名を引数として指定することで目的の要素のデータをすべて取り出します。getElementsByTagNameメソッドで取り出した個々のデータにアクセスする場合は,「item」メソッドを使用します。引数に数値を指定することで,指定した順番のデータにアクセスできます。
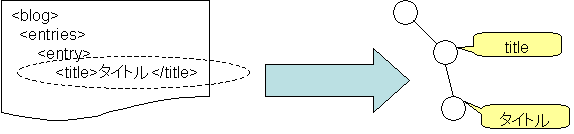
ここまでの処理で,title要素のデータが取り出せます。しかし,取り出せるのはXMLデータです。タイトル文字列だけを取得するにはどのような処理が必要なのでしょうか。面倒なように思えますが,この処理は,ある要素の(最初の)子要素を取得する「getFirstChild」メソッドと,その値を表示させる「getNodeValue」メソッドを使うだけで実現できます。なぜなら,DOMが使用する木構造では,要素内の文字列を子要素として表しているからです(図9)。
図9:要素内の文字列は子要素として管理される
文字列を取り出す処理は、子要素の内容を出力する処理と同義になります。
ここまでの処理をまとめると,タイトル文字列の一覧を取得するプログラムは図10のようになります。
図10:タイトル文字列を抜き出すPerlプログラムの例
XML::DOMモジュールを使っています。図4のプログラムとは違って出力がXMLデータではなく、テキスト・データになっています。
#!/usr/bin/perl
use utf8;
use NeoProxy; # HTTP API Perl implementation
use XML::DOM; # XML-DOM
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
$USERNAME = "Administrator";
$PASSWORD = "unitec";
$result = $my_proxy->login($USERNAME, $PASSWORD);
$result = $my_proxy->queryXML("/ND/blog/entries/entry/title");
print $result;
my $parser = new XML::DOM::Parser;
my $doc =$parser->parse($result);
my $title_nodes = $doc->getElementsByTagName("title");
my $nodelength = $title_nodes->getLength();
binmode STDOUT, ":utf8";
for my $i (0..($nodelength - 1)){
my $title_node = $title_nodes->item($i);
my $childnode = $title_node->getFirstChild();
my $title = $childnode->getNodeValue();
print "$title\n";
}
$result = $my_proxy->logout();
これにより,XMLデータのtitle要素から,タイトル文字列だけをテキスト形式で取得できます。このプログラムを「getTitle.pl」という名前で保存すると,その実行結果は次のようになります。
$perl getTitle.pl
ここまでできたら,あとはCGIプログラムとして変更すればBlog記事のタイトル一覧表示画面が完成します。CGIプログラムでは,HTTPヘッダーを付加したり,レイアウトの調整やリンク作成などの細かい処理を実施します。サンプル・コードを,本誌付録CD-ROMに「title_list.cgi」という名前で収録してあります。詳細はそちらをご覧ください。
なお,このCGIプログラムでは,プログラムの見通しを良くするために,コード中になるべくHTMLタグが入らないよう「HTML::Template」モジュールを使用しています。
「HTML::Template」モジュールは,別ファイルに切り分けた「テンプレート」と呼ばれるHTML文書のひな型を使ってデータを出力するためのPerlモジュールです。http://html-template.sourceforge.net/から入手できます。
同モジュールを利用すると,定型部分はテンプレートにしておき,動的に変化する文字列や数値だけを差し込んで出力できるようになります。処理とデザイン(HTML文書)を分離できますので,プログラム・コードやHTML文書の見通しが良くなる利点があります。
同モジュールの基本的な使い方を図11に挙げました。この例では,テンプレートとなるHTML文書に「MOJI」という変数を埋め込んでおき,その変数に「Hellow World」という文字列を設定してデータを出力しています。
図11:HTML::Templateモジュールの利用例
■ HTML文書部分の記述例
*以下の文書を「template.html」という名前で保存する
<html>
<head>
<title>Test Template</title>
</head>
<body>
<p>HTML::Template=<TMPL_VAR NAME=MOJI></p>
</body>
</html>
■ Perlプログラム部分の記述例
use HTML::Template;
# HTMLテンプレートをオープン
my $template = HTML::Template->new(filename => 'template.html');
# パラメータを埋める
$template->param(
MOJI => "Hellow World"
);
# 必須のContent-Typeを送信
print "Content-Type: text/html\n\n";
# テンプレートを出力
print $template->output;
このサンプルCGIプログラムにWebブラウザでアクセスすると写真1のような表示が得られます。
写真1:CGIプログラムの出力例
完成したCGIプログラムにWebブラウザでアクセスした様子です。
なお,Xprioriからの検索結果は,文字コードにUTF-8を使用します。PerlでのUTF-8の扱いについては,「PerlでのUTF-8データの扱い」を参照してください。
XprioriはND要素の子要素としてデータを格納
図3で示したBlog用のXMLデータには「ND要素」は存在しません。しかし,図4のプログラムで使うXQuery文では「ND要素」を最初に指定しています。これはなぜでしょうか。
これはXprioriのデータ格納の仕様が原因です。Xprioriでは,格納するXMLデータに独自の管理情報を付加して管理しています。この管理情報を格納する目的で,すべてのXMLデータをND要素の子要素として格納するのです(図A-1)。
このため,Xprioriでデータを検索する場合,XQueryの検索式は必ず「/ND」で始まることになります。「/ND」で始まらなかった場合,Xprioriはエラーを返す仕様になっています。
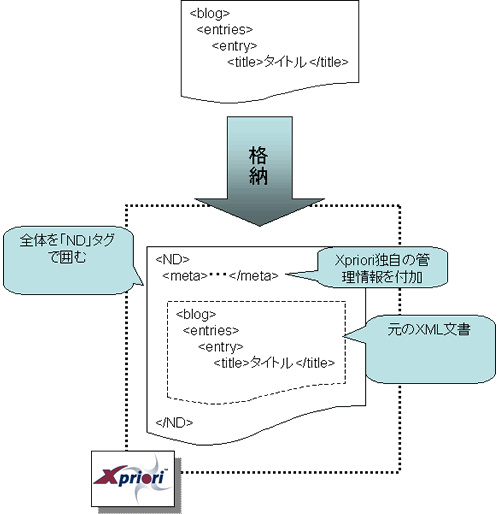
図A-1 XprioriのXML格納の特徴
PerlにおけるUTF-8データの扱い
Perlでは,バージョン5.6からUTF-8に実験的に対応し,バージョン5.8.0から正式にサポートしています。そのため,文字コードにUTF-8を使った文字列を正しく扱えます。
UTF-8文字列には内部的にフラグが立てられ,非UTF-8文字列と区別して処理されます。UTF-8文字列と非UTF-8文字列を連結する場合などは,全体をUTF-8文字列に変換(upgrade処理)してから連結処理が実施されます。
しかし,データを表示したり,ファイルなどに出力する際は,安全を考えてUTF-8文字列をASCII文字列に変換(downgrade処理)しようとします。もしもASCII文字の範囲外にある文字が存在した場合,警告が表示されます。例えば,print文でUTF-8文字列を出力しようとすると,図B-1のような警告が出力されます。
警告が出ないようにするには,出力環境でUTF-8文字列が問題なく利用できることをPerlインタプリタに教えてやる必要があります。これには例えば,print文の前に
という記述を加えます。これにより,標準出力にUTF-8文字列をそのまま(downgrade処理なしに)出力できるようになります。
Wide character in print at
getTitle3.pl line 33.
図B-1 データベース初期化の手順
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
