Xpriori(NeoCore)紹介:スキーマ定義なしでもXML文書を格納可能。独自のインデックス技術で検索を高速化
XMLデータベース「Xpriori」
(月刊DBマガジン 8月号のProduct Focusにて掲載)
※この記事掲載については編集部に了承。
株式会社日立システムアンドサービス
山本貴禎 YAMAMOTO Kiyoshi 赤澤一憲 AKASAWA Kazunori
「Xpriori(エクスプリオリ)」は、三井物産が国内販売しているXMLデータベース「NeoCoreXMS 3.0」の無償版である。データベースのサイズが1GB以内に制限されるなど、いくつかの機能的な制限が加えられているが、商用版とほぼ同等の機能が利用できる。本稿では、Xprioriの製品概要と、簡単なアプリケーションのソースコードを使ってXprioriのAPIの使い方を解説する。
XMLデータベースの利点
Xprioriは、XML文書をそのままの形式で格納できるXMLデータベースである。Xprioriの特徴を説明する前に、XMLデータベースの利点を明らかにしておこう。
ご存知のとおり、XMLはマークアップ言語の1つであり、開始タグと終了タグ、および、それらに囲まれた値を1つの要素として、1つ以上の要素のセットからなるテキストデータである。
LIST1は、XMLの最小単位である要素を表わしている。人の名前を示すXML要素として、<PersonName>という開始タグと</PersonName>という終了タグがあり、それらに囲まれた形で"日立太郎"という名前(値)が記述されている。これは「"日立太郎"という値を持ったPersonName要素」を意味する。XML文書は、こうした要素が1つないし複数集まって構成されている。

LIST1:XML要素
また、XMLは階層構造を持つことができる。LIST2は人を表わすXML文書であるが、1階層目には人の情報全体をくくるPerson要素があり、その中の2階層目には名前を示すPersonName要素や、郵便番号や住所を示すZip要素やAddress要素がある。電話番号は、固定回線用と携帯電話用など複数の番号を記述できるように、2階層目のPhone要素でくくるようにした上で、3階層目でPhoneNo要素を複数記述できるようにしている。
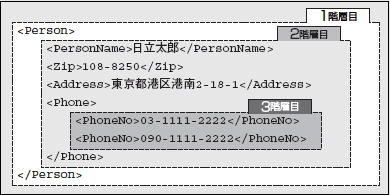
LIST2:XML文書の階層構造
階層構造を表現できるXML文書を従来の方法で保存しようとすると、さまざまな問題が生じる。例えば、OSのファイルシステム上にファイルとして保存することは最も簡単な方法であるが、トランザクション制御や検索の仕組みがないなどの理由から、最適とは言えない場合が多い。
また、データベースの代名詞ともなっているリレーショナルデータベース(以下、RDB)に格納する方法も考えられる。その場合、XML文書を階層ごとに分割して複数のテーブルにデータを格納する方法や(図1)、1つの文字列のカラムにXML文書全体を格納する方法がある(図2)。
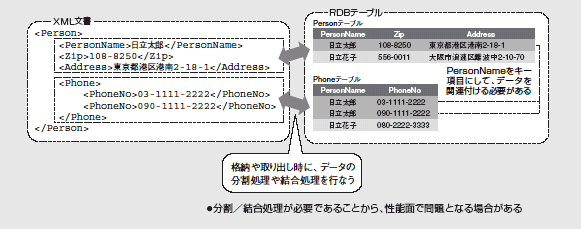
図1:XML文書を分割してRDBに格納する場合
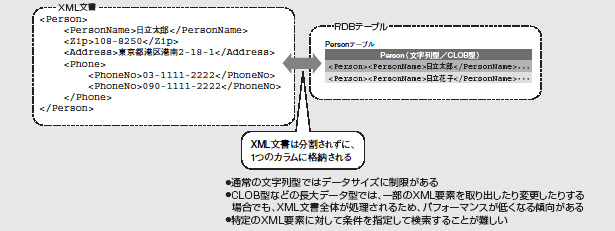
図2:XML文書をRDBのテーブルの1つのカラムに格納する場合
複数のテーブルを分割する方法では、XML文書を格納したり取り出したりする場合に、データの分割や結合の処理が必要になり、性能面で問題を抱える場合がある。
一方、XML文書を1個の文字列カラムに格納する方法では、通常の文字列カラムだとデータサイズの制限に引っかかる場合がある。また、CLOB(Character LargeOBject)などの長大データ用のタイプを利用すると、一部のXML要素を取り出したり変更する場合でも、RDB内ではXML文書全体の取り出し/格納処理が行なわれるため、処理速度に問題が出ることが考えられる。検索する場合を考えても、1つの文字列データとして格納されているので、特定のXML要素に対して条件を指定することは難しい。
これらの問題点により、XML文書を格納するためにファイルシステムやRDBを利用することは、最適なソリューションとは言えない場合が多い。
そこで、XML文書をそのままの形式で格納できるデータベースとして、XMLデータベースが開発されてきた。XMLデータベースでは、XML文書の格納や取り出しのたびにデータの分割や結合の処理が発生せず、文字列長の制限を気にする必要もない。また、XML文書全体だけではなく、一部のXML要素の出し入れも可能であると同時に、個々の要素に対して条件を指定して検索することも可能である。
今後、企業間や企業内のシステムの連携/統合の場面において、XMLの利用が確実視されている状況を考えると、XMLをそのままの形式で保存できるXMLデータベースを利用する場面も増えていくだろうと筆者は考えている。
Xprioriが持つ3つの特徴
Xprioriは、XMLデータベースの中でも、スキーマ定義が不要であるなどの特徴を持つことから、特にXML文書の構造が一定に決まらない場合に適した製品と言える。この特徴は、「DPP(Digital Pattern Processing)」と呼ばれる米国特許技術を利用した基本アーキテクチャが実現している。
DPPはパターン認識技術の一種である。Xprioriでは、これをインデックスの技術として利用している。XML要素と階層の情報をもとにインデックスを作成するのだが、DPPを利用すると階層の深さに関係なく固定長のインデックスデータが作成されるので、データサイズがコンパクトになるメリットがある。また、DPP技術によるインデックスのフェッチはデータ量に依存せずほぼ一定の性能を維持できるため、データ量が多くなっても一定の性能で検索が可能である。
以下、Xprioriの3つの特徴を説明する。
● スキーマ定義が不要
一般的にXMLデータベースは、XMLSchemaやDTD(Document Type Definition)などのスキーマ定義言語を使って、あらかじめ格納できるXML文書の形式を定義しておく必要がある製品が多い。しかし、Xprioriではスキーマ定義の必要がなく、ソフトウェアをインストールした直後から、整形式の(Well-formedな)XML文書なら、どんな文書でも格納できる。
この特徴を持つことから、XML文書の形式が完全に決まっていなくても、システム開発を進めることができる。開発を進めていく中でXML文書の形式が変更になった場合でも、XMLデータベースにスキーマを定義する必要がないために手間がかからない。この特徴は、いったん開発したシステムの機能拡張に伴って、XML文書の形式を変更しなければならなくなった場合にも有効である。
● フルオートインデックス
データベースは、XMLデータベースに限らず、インデックスによって検索性能を確保するのが一般的である。ほかのXMLデータベースではあらかじめデータベースにインデックスを定義しておく必要があるが、Xprioriではインデックスの定義は不要で、格納されたXML文書のすべての要素や値に自動的にインデックスが張られるために手間がかからない。
また先にも述べたとおり、XprioriのインデックスはDPP技術を利用してコンパクトになっているため、ディスクやメモリなどのリソースも比較的少なくて済む。
● 一定のパフォーマンス
これもDPP技術によって得られる特徴である。一般のインデックス技術では性能やリソースがデータ量に依存してしまうが、DPPではパターン認識であるため、XML文書の数、要素の名前や階層の深さ、データ量に依存せず、一定のパフォーマンスが得られる。
商用版「NeoCoreXMS」との違い
Xprioriは、三井物産から販売されている商用版XMLデータベース「NeoCoreXMS3.0」の無償版であり、非商用または個人利用を目的にしている場合に限り利用できる。開発元が米国エクスプリオリ(Xpriori)社であることから、無償版にこの名前を採用しているとのことである。現在は、Xprioriユーザー向けのコミュニティサイト「XMLDB.JP」(詳細は後述)において、Red Hat Linux 9.0対応のLinux版と、Windows 2000/XP/Server 2003対応のWindows版がダウンロード可能となっている。無償版提供について三井物産では、今後のXMLデータベースのユーザーの裾野を広げる狙いで実施していると述べている。
さて、Xprioriは無償版であるため、NeoCoreXMSと比べて次のような制約が設けられている。
- データベースのサイズが、約1GBに制限されている。
- Xprioriにアクセスできるのは、Xprioriをインストールしたコンピュータと同じIPアドレスからに制限されている。また、セッション数も1に制限されている。
- ホットバックアップ機能が利用できない。
- 正規のサポートや保守の対象外となっている。
これらの制約は、非商用または個人利用のみであることを考えれば許容範囲と言えなくもないが、ユーザーにとって気になるのは、4.の「サポートがない」ことだろう。これについては、XMLDB.JPサイトでユーザー同士の情報交換ができるので、困ったときにはこのサイトで相談してみると良い。
Xprioriを使ってみる
Xprioriには、データベース操作を行なうためのAPIと、各種の管理を行なうGUIやコマンドインターフェイスのツールが備わっている(図3)。
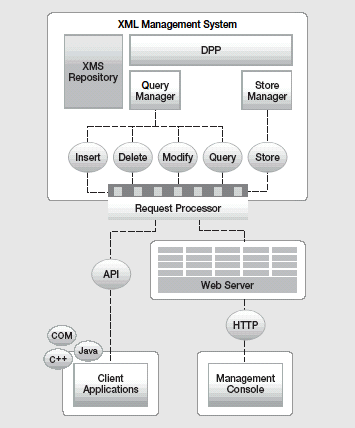
図3:Xpriori全体のアーキテクチャ
開発用のAPIとしては、Javaインターフェイスのほか、C++やCOMインターフェイスが提供されている。また、XprioriのAPIではトランザクションをサポートしている。
管理用ツールとしては、Webブラウザから利用できる「XMSConsole」(画面)とコマンドインターフェイスが提供されている。XMS Consoleでは、XML文書の操作をはじめ、各種コンフィグレーションの設定、ユーザーグループの管理やアクセス制御の設定が可能である。コマンドインターフェイスでは、データベースの作成などができる。
画面:XMS Console
● Java APIを使ったXML文書の格納と取り出し
ここからは、XML文書をXprioriに格納したり検索したりする簡単なJavaプログラムのソースコードを見ながら、XprioriのJava APIの基本的な使い方を解説する。
図4は、Xprioriにアクセスするための基本的な処理の流れを示したフローチャートである。まず、コネクションオブジェクトを生成し(①)、ユーザーとパスワードを指定してログインし(②)、トランザクションを開始する(③)。トランザクション開始後、XML文書を格納したり検索したりする操作のための処理を記述する(④)。XML文書の操作が終わったら、トランザクションをコミットし(⑤)、ログアウトする(⑥)。
なお、XprioriではXML文書の操作中に例外が発生した場合は、自動的にロールバックされるため、ロールバックの処理を書かずにログアウトのみを行なえばよい。
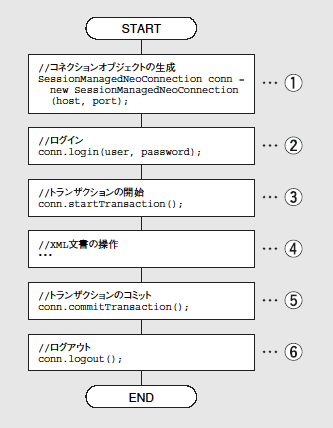
図4:Xprioriにアクセスするための基本的な処理の流れ
本稿では、人の情報を表現したXML文書を使うことにする。階層構造を図示すると、図5のようになっている。
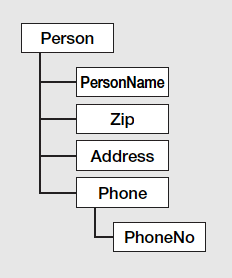
図5:人情報のXMLスキーマ(階層図)
まず、<Person>という全体をくくるタグが1 階層目にあり、2階層目に名前(<PersonName>タグ)と郵便番号(<Zip>タグ)と住所(<Address>タグ)が並んでいる。さらに複数の電話番号を持てるように<Phone>タグでくくる形で3階層目に<PhoneNo>タグがある。これを、XML文書の形式で示すとLIST3になる。
▼LIST3:Xprioriに入出力するサンプルXML文書
<?xml version="1.0" encoding="UTF-8" ?>
<Person>
<PersonName>日立太郎</PersonName>
<Zip>108-8250</Zip>
<Address>東京都港区港南2-18-1</Address>
<Phone>
<PhoneNo>03-1111-2222</PhoneNo>
<PhoneNo>090-1111-2222</PhoneNo>
</Phone>
</Person>
XprioriのAPIを使う際に知っておかなければならないことは、XML文書をデータベースに入出力する際の形式がテキスト形式である点である。XML文書をテキストの状態のままで個々の要素を扱うようなプログラムは書きづらいので、DOM(Document ObjectModel)などのJavaオブジェクトの形式で扱うようにするのが一般的である。したがって、プログラム中ではJavaのオブジェクトとして扱っておき、Xprioriに格納する直前でテキスト形式に変更したり、Xprioriから読み出した直後にJavaオブジェクトに変換したりするのがベターである。
なお、本稿ではプログラムを簡潔にするため、Java-XMLバインディングツール「Castor」を使用して、Javaオブジェクト形式とテキスト形式の間の変換を行なっている(図6)。Castorを利用すると、XMLスキーマからJavaクラスを自動生成することができる(Castorに関する詳細な解説はほかの記事に譲る)。

図6:Castorを使って、人情報のXMLスキーマからJavaのクラス群を自動生成する
では、実際に、XML文書の格納と検索のためのソースコードを見てみることにする。
● XML文書をXprioriに格納する
LIST4は、XML文書を格納するためのソースコードである。
▼LIST4:XprioriにXML文書を格納するプログラム
package sample;
//java.ioパッケージのクラス
import java.io.StringReader;
import java.io.StringWriter;
//CastorおよびCastorで自動生成されたクラス群
import org.exolab.castor.xml.Marshaller;
import sample.person.Person;
import sample.person.Phone;
//XprioriのConnectionクラス
import com.neocore.httpclient.SessionManagedNeoConnection;
//XprioriにXML文書を格納するプログラム
public class StoreXML {
public static void main(String[] args) {
SessionManagedNeoConnection conn = null;
String storeXml = null;
try{
//人情報の構築
//Casterで自動生成されたクラスに適宜、
//値をセットしながら人情報を構築 ・・・・・・・・・・・・・・・・・・・・・・・①
Person person = new Person();
person.setPersonName("日立太郎");
person.setZip("108-8250");
person.setAddress("東京都港区港南2-18-1");
Phone phone = new Phone();
phone.addPhoneNo("03-1111-2222");
phone.addPhoneNo("03-1111-2223");
person.setPhone(phone);
//マーシャル処理-格納するXML文書(文字列)を生成 ・・・・・・・・・②
StringWriter writer = new StringWriter();
Marshaller marshaller = new Marshaller(writer);
marshaller.setEncoding("UTF-8");
marshaller.marshal(person);
storeXml = writer.toString();
//人情報をXprioriに格納
//Xprioriへのコネクション取得
conn = new SessionManagedNeoConnection( ・・・・・・・・・・・・・・・・③
"localhost", 7701);
//ログイン
conn.login("user", "password"); ・・・・・・・・・・・・・・・・・・・・・・・・④
//トランザクション開始
conn.startTransaction(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・⑤
//Personの格納
conn.storeXML(storeXml, null, null); ・・・・・・・・・・・・・・・・・・・⑥
//トランザクションのコミット
conn.commitTransaction(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・⑦
} catch (Exception e) {
e.printStackTrace();
} finally {
//ログアウト
if (conn != null) {
try {
conn.logout(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・⑧
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
XML文書を格納するための命令は、SessionManagedNeoConnection#storeXML()メソッドを使用している(LIST4の⑥)。1つのXML文書がRDBでの1つのレコードに相当すると考えてみれば、storeXMLメソッドは、RDBにおけるSQLのINSERT文と同様の役割を持つAPIだと考えると理解しやすい。
なお、insertXMLという名前の別のメソッドも存在するが、こちらのメソッドは指定されたXML文書の中に要素を追加するためのメソッドである。RDBに慣れたユーザーにとっては、メソッド名がもとで誤解しやすいので注意が必要である。
それでは、ソースコードの説明に移る。まず、Castorで自動生成したJavaクラスに氏名などのデータを格納しながら人情報のXML文書を構築し(LIST4の①)、完成したらXML文書をテキスト形式で取り出す(LIST4の②)。次に、Xprioriにコネクションを確立して(LIST4の③)、ログインし(LIST4の④)、トランザクションを開始する(LIST4の⑤)。その後、storeXMLメソッドでXML文書を格納し(LIST4の⑥)、トランザクションをコミットして(LIST4の⑦)、ログアウトする(LIST4の⑧)。以上が、XprioriにXML文書を格納する処理である。
● Xprioriに格納されているXML文書を検索する
LIST5は、XML文書を検索するためのソースコードである。Xprioriでは、検索式としてXPathとXQueryの2つの方法を利用できるが、本稿ではXPathによる検索方法を紹介する。
▼LIST5:Xprioriに格納されているXML文書を検索するプログラム
package sample;
//java.ioパッケージのクラス
import java.io.StringReader;
import java.io.StringWriter;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.stream.StreamResult;
import javax.xml.transform.stream.StreamSource;
//CastorおよびCastorで自動生成されたクラス群
import org.exolab.castor.xml.Marshaller;
import sample.person.Person;
import sample.person.Phone;
//XprioriのConnectionクラス
import com.neocore.httpclient.SessionManagedNeoConnection;
//Xprioriに格納されているXML文書を検索するプログラム
public class QueryXML {
public static void main(String[] args) {
//氏名をキーに人情報を検索
String queryResultsXml = null;
SessionManagedNeoConnection conn = null;
String query = "/ND/Person[PersonName='日立太郎']"; ・・・・・・・①
try {
//Xprioriへのコネクション取得
conn = new SessionManagedNeoConnection( ・・・・・・・・・・・・・・・・・②
"localhost", 7701);
//ログイン
conn.login("user", "password"); ・・・・・・・・・・・・・・・・・・・・・・・・・③
//トランザクションの開始
conn.startTransaction(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・④
//検索実行
queryResultsXml = conn.queryXML(query); ・・・・・・・・・・・・・・・・・⑤
//トランザクションのコミット
conn.commitTransaction(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・⑥
} catch (Exception e) {
e.printStackTrace();
} finally {
//ログアウト
if (conn != null) {
try {
conn.logout(); ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・⑦
} catch (Exception e) {
e.printStackTrace();
}
}
}
try {
//検索で取得したXMLから<Query-Results>タグを
//取り除いてPerson要素以下のXML要素を取得する ・・・・・・・・・・・・⑧
String xslFile = "/tmp/Person.xsl";
StringReader reader =
new StringReader(queryResultsXml);
StreamSource source = new StreamSource(reader);
StringWriter writer = new StringWriter();
TransformerFactory factory =
TransformerFactory.newInstance();
Transformer transformer =
factory.newTransformer(
new StreamSource(xslFile));
transformer.transform(
source, new StreamResult(writer));
String personXml = writer.toString();
//取得したXMLからPersonオブジェクトを生成
Person person = Person.unmarshal( ・・・・・・・・・・・・・・・・・・・・・・・⑨
new StringReader(personXml));
//Personオブジェクトの要素を出力
System.out.println(person.getPersonName());
System.out.println(person.getZip());
System.out.println(person.getAddress());
System.out.println(person.getPhone().getPhoneNo(0));
System.out.println(person.getPhone().getPhoneNo(1));
} catch (Exception e) {
e.printStackTrace();
}
}
}
コネクションの確立からログアウトまでは、XML文書の格納と同じ流れである(LIST5の②~⑦)。XML文書の検索には、SessionManagedNeoConnection#queryXML( )メソッドを使用している(LIST5の⑤)。また、検索で取り出したテキスト形式のXML文書をCastorで自動生成したJavaオブジェクトに変換する処理も行なっている(LIST5の⑨)。
▼LIST6:検索結果で取得したXML文書| <?xml version="1.0" encoding="UTF-8" ?> <Query-Results> ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・①
|
Xprioriで検索する場合に注意すべき点が2つある。
1つ目は、検索の条件についてである。Xprioriでは、すべてのXML文書が<nd>というXpriori特有のルート要素の下位に格納されている。そのため、検索時には<nd>というルートタグが存在していることを念頭において、XPathなどの検索式を記述する必要がある。ソースコードでは、先頭には<nd>タグを含めた形で条件を指定している(LIST5の①)。
2つ目は、検索した結果はXML文書として返却されるのだが、ルートタグに<Query-Results>タグが付与されていることである(LIST6の①と③)。これは、複数件のXML文書がヒットした場合にそれらをくくるタグが必要になるためである。複数件ヒットした場合は、2階層目の<Person>タグが複数回出現するようなXML文書として受け取ることになる(LIST6の②)。
なお、本稿では1件だけヒットすることを想定して、XSLTを使って<Query-Results>タグを除去している(LIST5の⑧とLIST7)。
▼LIST7:<Query-Results>を除去するためのXSLスタイルシート
<?xml version="1.0" encoding="shift_jis" ?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" >
<xsl:template match="/Query-Results/Person">
<xsl:copy-of select="."/>
</xsl:template>
</xsl:stylesheet>
本稿では誌面の都合上、XML文書を格納するstoreXMLメソッドと検索するqueryXMLメソッドだけを紹介した。ほかの基本的なAPIとしては、XML文書を更新するmodifyXMLメソッド、XML文書に要素を追加するinsertXMLメソッド、XML文書の一部または全部を削除するdeleteXMLメソッドが提供されている。
コミュニティサイト「XMLDB.JP」
5月20日より、Xprioriユーザーのための総合情報サイト「XMLDB.JP」(https://www.xmldb.jp/)が公開されている。このサイトは、Xprioriユーザーの互助体制の確立を目的にしたもので、三井物産、日本ユニテック、アットマーク・アイティが共同で企画/運営している。
このサイトでは、Xpriori自体やサンプルプログラムをダウンロードできるほかに、Xprioriのチュートリアルや解説記事、データベースサイズの見積り方法などが掲載されている。また、開発者同士で情報交換ができるフォーラムが開設されており、困ったときの相談や「こんな使い方ができるよ」といった情報発信の場として、ぜひ有効に活用されたい。
XMLデータベースは、RDBを代替するものではなく、それぞれの利点や欠点を知った上で、適材適所で使い分けていくことが望ましい。適材適所を見定めるためには、実際に使ってみて評価したいところである。
現在、フリーのXMLデータベースや、商用版の無償評価ライセンスを入手できる製品も出てきているが、本稿で紹介したXprioriは、商用版と非常に近い状態でリリースされているため、本番稼動時にかなり近い状態で製品評価ができるはずだ。階層構造を持っているデータを扱う場合はもちろん、特にデータ形式が頻繁に変更されるようなシステムにXprioriを試用してみて、XMLデータベースの利用箇所や可能性について検討されることをお勧めする。
| 動作環境 | Linux版:Red Hat Linux 9.0 Windows版:Windows 2000/XP/Server 2003 |
|---|---|
| 製品/情報の入手先 | Xprioriに関するWebサイト「XMLDB.JP」 https://www.xmldb.jp/ |
| 山本貴禎(やまもときよし) | 赤澤一憲(あかさわかずのり) |
|---|---|
| 1986年、日立西部ソフトウェア株式会社(現:株式会社日立システムアンドサービス)に入社。現在はJava、.NET、XMLのシステム提案やコンサルティング業務に従事。 | 2000年、株式会社日立システムアンドサービスに入社。現在はJava、XMLの技術コンサルティングやアーキテクチャ設計に従事。 |
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
