作って学ぶXMLデータベースNeoCore XMS実践 第3回
![]()
![]()
著者:ウルシステムズ 最上 隆史 2006/3/31
前回は、半定型文書である提案書を扱うシステムの機能とXMLデータ構造の設計を行いました。半定型文書である提案書は、全体的には自由に編集できる非定型ですが、システムによっては自動処理できる定型部分を持つ必要があります。
このため、本連載ではXMLフォーマットを採用したプレゼンテーションツール「Impress」を使ってユーザが自由に作成できる提案書を扱い、特定のテキスト要素に決まったオブジェクト名やスタイルを与えるというルールを設けることで定型部分を持たせることにしました。
第3回目ではXMLデータベースを構築して半定型文書である提案書を登録するところまでを、実際の作業手順にそって紹介します。その後、登録した提案書の定型部分を用いて情報を取得するための検索式を検討します。
まず最初に、使用するXMLデータベースであるNeoCore XMSの評価版をインストールして、データベースを構築するまでの手順を紹介します。RDBとは違って、スキーマを定義することなく非常に簡単に構築できることを確認してください。
ここでインストールの前に、NeoCore XMSの特徴を表1に整理しておきます。
- DPPを用いた高速検索
- データ量が増えてもデータ構造が複雑化しても一定の速度でパターンマッチングできる特許技術DPPを利用して検索の高速化を実現。
- フルオートインデックスを採用
- すべてのタグに対して自動的にインデックスを設定するため、インデックス設計することなく高速検索が可能。
- ウェルフォームドXMLに対応
- データベースのスキーマを定義することなく任意の構造のXMLを格納し、検索の対象にすることが可能。
- 標準問い合わせ言語XPath、XQueryに対応
- データベース製品に依存しない標準問い合わせ言語であるXPathとXQueryを用いた検索に対応(注1)。
▲表1:NeoCore XMSの特徴
※注1:現時点(2006年3月)ではXQuery 1.0の標準化は完了していないため、一部order by(sort byとして実装)、Typeswitch、Quantifiedなどは未実装となっている。XQuery 1.0の標準化完了にあわせて完全な準拠を行う予定。
それでは、NeoCore XMSのインストールに進みましょう。
NeoCore XMSの評価版を入手するまず、NeoCore XMSの提供元であるサイバーテックから、NeoCore XMSの評価版を入手します。サイトにアクセスして、「"NeoCore XMS"評価版お申し込みフォーム」のページに行き、そこからユーザ登録を行います。ユーザ登録が終わると、サイバーテックからメールでダウンロード先のURLが送付されますので、そのURLから評価版をダウンロードします。なお、今回試用するバージョンはNeoCore XMS-3.1.3.52-jpになります。
その後、今度は株式会社サイバーテックから30日間限定のライセンスファイル(license.xml)が送られてきます。このライセンスファイルはNeoCore XMSのインストール手順を進める中で、所定のディレクトリ(デフォルトではC:\NeoCore\neoxml\config)に置くことが指示されます。
次にダウンロードしたNeoCore XMSをインストールします。ダウンロードした評価版を解凍するとインストーラファイル(xms-3.1.3.52-jp-win32.exe)が取り出されます。このインストーラを起動し(図1)、指示に従って必要な項目を設定していきます。
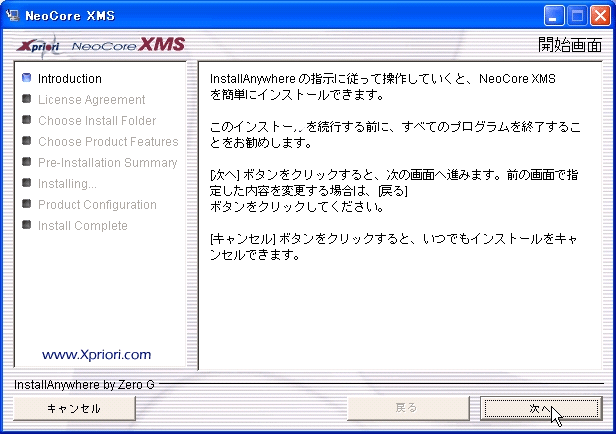
▲図1:NeoCoreインストーラの起動直後
(画像をクリックすると別ウィンドウに拡大図を表示します)
インストール中にデフォルトのロケールとエンコーディングを指定する画面が表示されます(図2)。今回使用するImpressのファイルのエンコーディングがUTF-8であるため、NeoCore XMSのデフォルトエンコーディングもあわせてUTF-8にします。
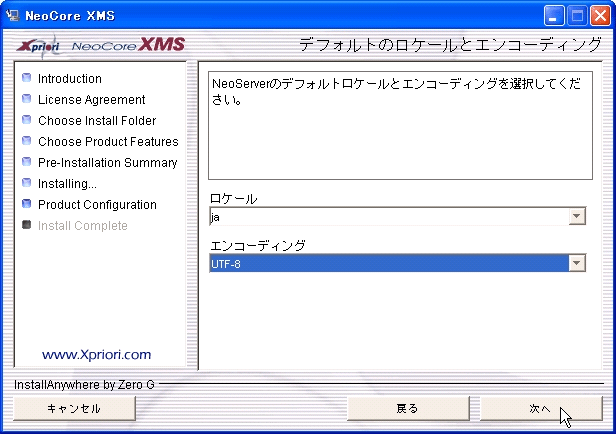
▲図2:デフォルトのロケールとエンコーディングを設定
(画像をクリックすると別ウィンドウに拡大図を表示します)
次にNeoServerが用意している管理コンソール画面にアクセスするためのユーザ名、パスワード、ポート番号を設定します(図3)。ここでは、ユーザ名をConsoleとしていますが、自由に設定してかまいません。
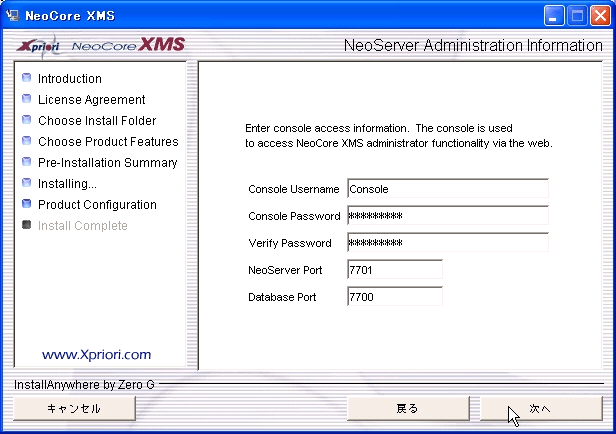
▲図3:NeoServerの管理コンソール用アカウントの設定
(画像をクリックすると別ウィンドウに拡大図を表示します)
この画面で入力したユーザ名とパスワードは管理コンソール画面にアクセスするための専用アカウントです。データベース内の情報にアクセスするためのアカウントではありません。
次にデフォルトのアクセス制御(注2)を適用するために「Load Default Access Control Documents」チェックボックスにチェックします。
※注2:デフォルトのアクセス制御とは、必ず作成されるAdministratorユーザとguestユーザのそれぞれに標準的な操作権限を適用するためのルールをあらわしています。
最後にデータベース内の情報にアクセスするためのユーザ名/パスワードを設定し、「Create Database」ボタンをクリックします。この操作によってデフォルトのデータベースが作成されます(図4)。
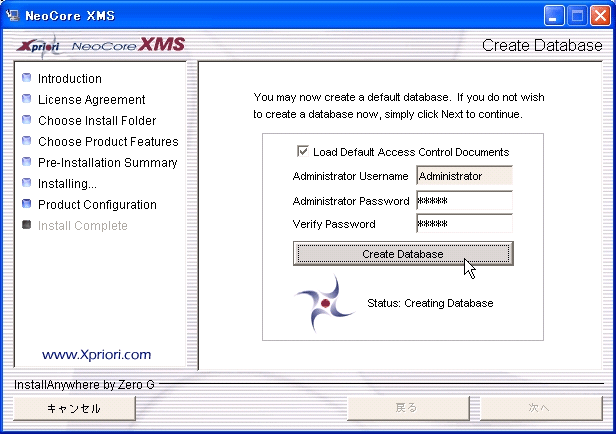
▲図4:データベース用アカウントの設定とデフォルトデータベースの作成
(画像をクリックすると別ウィンドウに拡大図を表示します)
インストールが完了すると、WindowsのメニューにNeoServerを起動するための「Start NeoServer」、停止するための「Stop NeoServer」、管理コンソールを開くための「Launch XMS Console」が作成されます。NeoCore XMSをインストールしたディレクトリ(デフォルトではC:\NeoCore\docs\manuals)にPDFのマニュアル(日本語)がインストールされますのでNeoCore XMSの詳細な情報を知りたいときはそちらを参照してください。
これでXMLデータベースを使用する準備が整いました。
次に半定型文書である提案書をXMLデータベースに登録します。RDBと違ってスキーマもデータ型もまったく意識することなく、非常に簡単に登録できることを確認してください。
今回、XMLデータベースに登録する提案書を図5に示します。
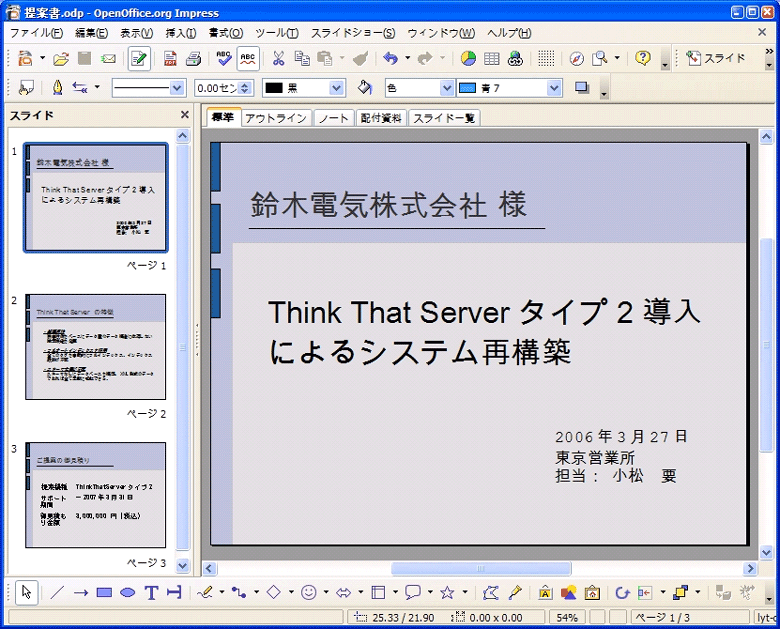
▲図5:登録する提案書(Impressの文書)
(画像をクリックすると別ウィンドウに拡大図を表示します)
提案書のImpress文書ファイル(提案書.odp)は以下のように複数のファイルで構成されたZIP形式のファイルとなっています。

▲図6:文書ファイルの構成
「content.xml」はお客様名や提案タイトルなどのテキストが含まれた提案書本体の情報を持つファイルであり、それ以外はスタイルなどの各種設定情報をあらわしたファイルとなります。今回のシステムでは、「content.xml」をデータベースで管理することにします。実際にXMLデータベースに登録するために、「提案書.odp」をZIPが扱えるツールで解凍して「content.xml」を取り出しておきます。
NeoCore XMSにストアするWindowsのメニューより「Launch XMS Console」を実行するとwebブラウザが起動され、NeoCore XMSコンソールのログイン画面(図7)になります。インストール時に設定したアカウントでログインすると、NeoServerの管理コンソール画面が表示されます。
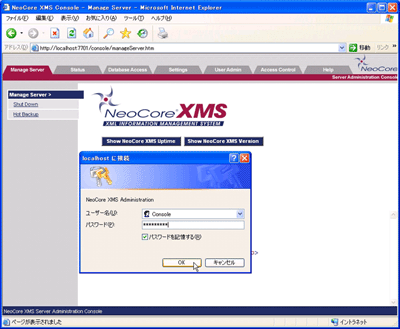
▲図7:NeoCore XMS管理コンソール画面
(画像をクリックすると別ウィンドウに拡大図を表示します)
ログイン後の画面上部にある「Database Access」タブをクリックし、インストール時に設定したデータベース管理者のアカウントを使ってログインします(図8)。

▲図8:データベースにログイン
(画像をクリックすると別ウィンドウに拡大図を表示します)
なお、コンソール画面にはこれ以外のタブとして、「Manage Server」「Status」「Setting」「User Admin」「Access Control」などがありますが、これらを使うことでサーバの設定やユーザアカウントの管理を行うことができます。
次に、画面左ペインの「Store」をクリックすると、XML文書を登録するためのウィンドウ(図9)が表示されます。先ほど解凍して取り出した「content.xml」を適切なディレクトリに配置し、ウィンドウ上の「XML File」欄に「content.xml」を配置したパスを指定します。そして「Store XML」ボタンをクリックします。
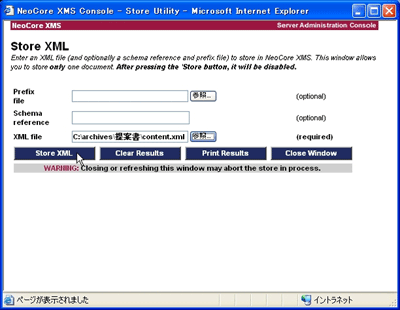
▲図9:ZIP解凍したcontent.xmlを指定してXMLデータベースにストアする
(画像をクリックすると別ウィンドウに拡大図を表示します)
これで、提案書内のテキストをXMLデータベースに登録することができました。営業支援システムの提案書登録機能では、ここまでの手順をプログラムで実現することになります。
- 提案書をアップロードする
- アップロードされた提案書を解凍し、content.xmlを取り出す
- 取り出したcontent.xmlをXMLデータベースにストアする
▲表2:ここまでの手順
検索式を設計する次は登録した提案書のデータを取り出すための検索式について検討します。
RDBからデータを検索するために、データベース製品によらない標準の問い合わせ言語としてSQLが用いられるように、XMLデータベースからデータを検索するには、標準の問い合わせ言語であるXPathやXQueryが用いられます。
まず、XPathとXQueryがどのようなものかを表3に示します。
- XPath
- XML文書の特定条件を満たす要素を指し示すための表現式。XSLやXQueryといったXMLの操作や検索をするための手段の一部として広く使われている。条件を記述できるので、それだけで検索式として利用することもできる。
- XQuery
- 複数のXML文書の要素間の複雑な関係を条件にした検索を可能にする表現式。RDBのSQLに相当するもので、where節を含むFLWR構文が使われ、検索結果を新たなXML文書として取得できる。
表3:XPath、XQueryとは
今回構築する営業支援システムで必要な検索要件もこれらのXPath、XQueryを利用して実現します。
今回構築する営業支援システムで必要な検索要件とは前回、営業支援システムで必要となる検索要件には以下の2つがあることを説明しました。
- 項目指定による検索
- お客様名などのオブジェクト名を持つ定型部分の値を検索し、対象となる提案書を見つける。
- フリーワード検索
- 指定されたキーワードを含むような提案書を見つける
▲表4:必要となる検索要件
上記それぞれの検索を実現する検索式を検討します。
項目指定による検索単純な項目指定の検索なので、XPath式によって行うことにします。
「content.xml」ファイルの内、「お客様名」をあらわす部分を以下に示します。XPath式では、XML文書のルートとなる要素(ここではdocument-content)から、配下の要素を「/」を使って順次特定していくのが基本になります。
<?xml version="1.0" encoding="UTF-8"?>
<office:document-content>
<office:body>
<office:presentation>
<draw:page draw:name="page1" draw:style-name="dp1" draw:master-page-name="標準">
<draw:frame draw:name="お客様名" draw:style-name="gr1">
<draw:text-box>
<text:p text:style-name="P1">鈴木電気株式会社</text:p>
</draw:text-box>
</draw:frame>
<draw:frame draw:name="提案タイトル" draw:style-name="gr2">
<draw:text-box>
<text:p text:style-name="P2">
<text:span text:style-name="T1">Think That Server</text:span>
<text:span text:style-name="T1">タイプ</text:span>
<text:span text:style-name="T1">2</text:span>
<text:span text:style-name="T1">導入によるシステム再構築</text:span>
</text:p>
</draw:text-box>
</draw:frame>
</draw:page>
</office:presentation>
</office:body>
</office:document-content> |
▲content.xmlの内、「お客様名」をあらわす部分
※注: サンプルのため一部省略しています。
例えば、「お客様名」と名付けたられたオブジェクトは「/document-content/body/presentation/page」で指定される要素の配下にある1つ目の「frame」要素です。この要素にname属性として「お客様名」が定義されていて、そのまた複数階層配下の「p」要素に含まれるテキストが実際のお客様名(ここでは[鈴木電気株式会社])をあらわしています。なお、office:、draw:、text:といった形式がたくさんでてきますが、これで示されているのは名前空間でありここでは無視してかまいません。
XPath式の組み立てそれでは具体的に、お客様の名前に「鈴木」が含まれるようなオブジェクトを検索するためのXPath式を組み立ててみましょう。表5の3つのステップに分けて考えていきます。
| 検索処理の要求 | 左記を実現するXPath式 | |
| ステップ1 | 「お客様名」という属性を持った「frame」要素を持つオブジェクトの上位項目を指定 | /document-content/body/ presentation/page |
| ステップ2 | ステップ1で指定したパス配下にあるname属性が「お客様名」という値を持っているような「frame」要素を指定 | </frame[@name='お客様名'] |
| ステップ3 | ステップ2で指定した要素のうち、複数階層配下のテキストにユーザが入力した検索値(ここでは「鈴木」とする)が含まれるという条件を指定 | ⁄⁄*[contains(text(),'鈴木')] |
表5:XPath式の組み立て
ステップ1で、「/document-content/body/presentation/page/」までのロケーションパスが特定できない場合には、パスのワイルドカードを使って「/document-content/body//」や「//page」などにしてもかまいません。
こうして以下に示すXPath式が得られます。
/ND/document-content/body/presentation/page/frame[@name='お客様名']??*[contains(text(),'鈴木')] |
▲お客様名を検索するためのXPath式
実際に検索してみた結果を以下に示します。
<Query-Results> <text:p text:style-name="P1">鈴木電気株式会社</text:p> </Query-Results> |
▲項目指定による検索結果
※注: サンプルのため一部省略しています。
フリーワード検索フリーワード検索では、提案書に含まれるすべてのテキストデータから指定されたキーワードを検索し、ヒットした文書の一覧(お客様名、提案タイトルなど)を取得します。このため、XPathよりも複雑な検索式が利用でき、かつ検索結果のフォーマットを指定できるXQueryを用いることにします。
XQueryの構文はFLWRと呼ばれますが、「For:XMLデータの繰返し処理」「Let:変数に代入」「Where:条件を指定」「Return:結果出力の指定」の頭文字をとったものです。
それでは、XQuery式を以下の3つのステップに分けて組み立てていきます。具体的にキーワードとして「システム」を指定して検索し、ヒットした文書のお客様名と提案タイトルを取得するXQuery式を検討します。
| 検索処理の要求 | 左記を実現するXQuery式 | |
| ステップ1 | 検索の対象とする要素のロケーションパスを指定し、$dataというループ変数で参照 | $data in /document-content /body/presentation |
| ステップ2 | ステップ1で指定した$dataの配下のすべてのテキストについて、'システム'というキーワードを含んでいるものという検索条件を記述 | contains($data//text(),'システム') |
| ステップ3 | 検索結果に出力するお客様名と提案タイトルのテキストをそれぞれ$client、$titleで参照 | $client := $data//frame[@name='お客様名'] //text() $title := $data//frame[@name='提案タイトル'] //text() |
▲表6:XQuery式の組み立て
こうして、以下に示すXQuery式が得られます。
for $data in /ND/document-content/body/presentation
let $client := $data//frame[@name='お客様名']//text()
,$title := $data//frame[@name='提案タイトル']//text()
where contains($data//text(),'システム')
return
<result>
<client>{string($client)}</client>
<title>{string($title)}</title>
</result> |
▲「システム」を含むような提案書を検索するためのXQuery式
実際に検索してみた結果を以下に示します。
<Query-Results>
<result>
<customer>伊藤証券株式会社</customer>
<title>Think DX Serverを利用した基幹システムの導入効果</title>
</result>
<result>
<customer>佐藤運輸株式会社</customer>
<title>Think SCM Serverを利用したSCMシミュレーション構築</title>
</result>
<result>
<customer>鈴木電気株式会社</customer>
<title>Think That Serverタイプ2導入によるシステム再構築</title>
</result>
</Query-Results>
|
▲フリーワード検索による検索結果
これで、Impress文書をXMLデータベースに登録する手順や、項目検索・フリーワード検索の実現方式が明確になりました。次回は検討した結果を使って、営業支援システムを構築していきます。
▲このページのTOPへ






