Blogサイト構築で理解するXMLデータベース 第3回
※日経Linuxにて掲載。この記事掲載については編集部に了承。


第3回 記事管理機能を追加してBlogサイトが完成
日本ユニテック 吉田 晃伸
3回にわたった連載も今回が最終回です。今回は,XMLデータベースに格納したBlog記事に対し,検索や追加,更新,削除といった機能を提供するプログラムを作成します。これにより,ひと通りの機能を備えたBlogサイトが完成します。それに合わせて,XMLデータベースの便利な使い方を紹介していきます。
記事の詳細を表示する
前回は記事のタイトルを表示する部分までを作成しました。今回は最初に,記事の詳細を表示する機能を作り込んでいきましょう。記事詳細は,一覧表示した記事タイトルをクリックすると表示させることにします。
本連載で構築するBlogシステムでは,XMLデータベースのクエリー言語であるXQueryで「/ND/blog/entries/entry」と示される場所に記事の詳細情報を格納しています。そこで,これを取り出す場合は「/ND/blog/entries/entry」というクエリーを使えば良いように思えます。しかし,これではデータベース内に存在するすべての「entry」要素が結果として返ってきます。
実際に,ある特定の記事の詳細情報を取り出すには,XQueryで情報を絞り込むのに使われる「述語」を活用しなければなりません。XQueryの述語は,SQL 文ならばSELECT句とFROM句で対象となったテーブル・フィールドをさらに絞り込むためのWHERE句の記述に相当するものです。要素位置指定に続いて大括弧(かっこ)を使って指定します(図1)。
図1:述語によって対象要素を絞り込む
XQueryで要素の絞り込みに利用するのが「述語」です。SQLのWHERE句のように利用します。
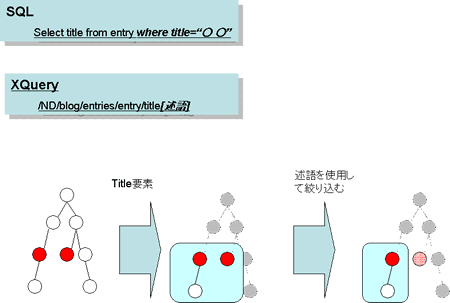
述語に数字を指定すると,該当する要素のうち,指定した順番のものだけが結果として返ってきます。これを利用すれば,図2のようなPerlプログラムで1番目の記事を取り出せます。なお,この数値の指定は「1」から始まることに注意してください。プログラムで配列を使う場合など,最初のデータを取り出すのに「0」を指定しますが,XQueryでは「1」を指定します。
図2:述語を使ったプログラム例
1番目の記事を取り出すプログラムの例です。述語で記事要素の番号を指定しています。
#!/usr/bin/perl -w
use NeoProxy; # HTTP API Perl implementation
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
#Xprioriにログイン
$result = $my_proxy->login("Administrator", "admin");
$xpath = "/ND/blog/entries/entry[1]";
#クエリーを実行
$query_result = $my_proxy->queryXML($xpath);
$result = $my_proxy->logout($query_result);
print $query_result;
任意の記事番号の記事詳細を表示するCGIプログラムを「entry_view.cgi」として作成します。その内容の一部は図3の通りです。記事番号は0から始まりますので,渡された記事番号に1を加えてからクエリーを発行しています。また,これに合わせて,前回作成した記事タイトルの一覧表示用のCGIプログラムを記事の番号を渡すように変更します。
図3:記事詳細表示用のCGIプログラム
一部だけを抜き出しています。完全なプログラムは本誌付録CD-ROMに「entry_view.cgi」という名前で収録しています。
#記事の番号を受け取る
$blog_id = $q_cgi->param('blog_id');
#指定された記事を取得する
#XPathを作成
$blog_id++;
$xpath = "/ND/blog/entries/entry[$blog_id]";
#クエリーを実行
$query_result = $my_proxy->queryXML($xpath);
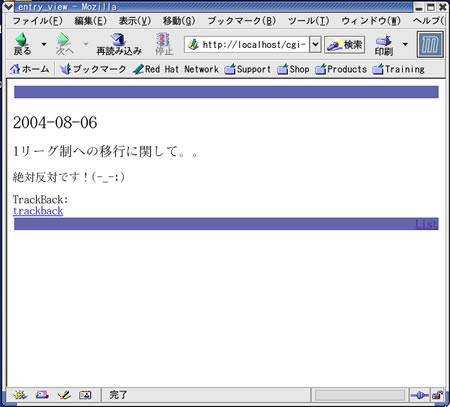
entry_view.cgiによる記事詳細の表示例が写真1です。
写真1 記事詳細の表示例
entry_view.cgiの実行結果です。
述語による高度な検索
述語に指定できる内容は数値だけではありません。XQueryでは述語の活用により,(1)データの存在の有無による検索,(2)文字列による検索,(3)数値の範囲による検索,(4)それぞれを組み合わせた検索などに対応できます。
例えば,述語にXML要素や属性を指定すると,それらの要素や属性が存在するものだけに結果を絞り込めます。これまでに用意したBlog用のデータの場合,図4のようなXQueryを使うと,トラックバックURL(trackback要素)が存在する記事だけを取り出せます。述語に指定するのが属性の場合は,属性名の前に「@」を付けます。
図4:トラックバックURLを持つ記事を抜き出すXQuery例
述語に要素名や属性名を指定すると、それを持つ要素が抜き出されます。属性名を指定する場合は属性名の前に「@」を付けます。
要素内の文字列を使った検索もできます。述語に「要素名= "検索文字列"」と指定すれば,要素が持つ文字列により結果を絞り込めます。逆に「要素名!= "検索文字列"」のように「!=」を使用すると,検索文字列が含まれないかどうかで絞り込めます。たとえば,「アニキ!」というタイトルを持つ記事を検索したい場合,図5のようなXQueryとなります。
図5:文字列検索する場合のXQuery例
「アニキ!」というタイトルを持つ記事を検索する場合のXQuery例です。
ただし,この方法では部分文字列を用いた検索に対応できません。要素内の文字列が,検索文字列と完全一致しないと対象と見なされないためです。部分文字列で検索したい場合,XQueryに用意された表1の関数を使用します。
表1:部分文字列検索用のXQuery関数
| 用途 | 関数 | 解説 |
|---|---|---|
| 部分一致検索 | contains (対象要素,検索文字列) |
対象要素内に指定された検索文字列が含まれるかどうかで絞り込みます |
| 前方一致検索 | starts-with (対象要素,検索文字列) |
対象要素内の文字列が検索文字列で始まるかどうかで絞り込みます |
| 後方一致検索 | ends-with (対象要素,検索文字列) |
対象要素内の文字列が検索文字列で終わるかどうかで絞り込みます |
例えば,「連勝」という文字列が含まれる記事を検索したい場合,図6のようなXQueryを利用します。
「連勝」という文字列を含む記事を検索する場合のXQuery例です。
| /ND/blog/entries/entry[contains(contents,"連勝")] |
文字列検索の特別な形として,数値による検索もできます。XQueryでは,要素に含まれる文字列が数字だけの場合,それを数値とみなして,大小の比較による検索ができます。数値の比較に使える演算子としては「>」,「<」,「>=」,「<=」があります。これらの記号の意味は数学で使用されるものと同じ意味を持ちます。
ここまでは条件を1つだけ指定して絞り込みしていましたが,複数の条件を組み合わせることもできます。それには,述語に複数の条件を記述し,キーワード(これを論理演算子と呼びます)で結び付けます。論理演算子には「and」(左右の条件を共に満たす)と,「or」(左右の条件のどちらかを満たす)の2つがあります。論理演算子は左側から評価されますが,andのほうが優先度が高くなっています。
条件文と論理演算子はいくつでもつなげられます。例えば図7のような長い述語も記述できます。これは,「連勝」という文字列を含む記事と,「反対」という文字列を含んだタイトルが「アニキ!」という記事をすべて取り出すクエリーの例です。
図7:論理演算子で複数の条件を指定できる複数の検索条件を指定する場合は、「and」または「or」という論理演算子を利用します。優先順位はandの方が高くなっています。
| /ND/blog/entries/entry[contains(contents,"連勝") or contains(contents,"反対") and title = "アニキ!"] |
新しい記事を追加する
続いて,新しいBlog記事を追加する機能を作ります。
さて,Blog記事を追加するとは,具体的にはどういう作業を指すのでしょう。それは,XMLデータベースに新しい「entry要素」を追加することにほかなりません(図8)。
図8 記事の追加はentry要素の追加に相当 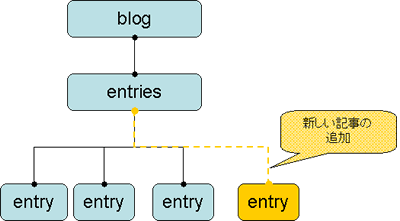
Xpriori では,新しいXML要素を追加するメソッドとして「insertXML」を用意しています。このメソッドは,XQuery式と挿入するXML文字列の2つの引数を必要とします。最初の引数のXQuery式で指定された要素の直後に,2つ目の引数で指定したXML文字列を挿入します。
さて,Blog記事を追加する場合のXQuery式はどうなるでしょうか。以下のような指定で正しいでしょうか?
| /ND/blog/entries/entry |
実はこれは誤りです。この場合,すべての「entry要素」が対象となってしまい,すべての「entry要素」の後ろに,XMLの文字列が追加されることになります(図9)。
図9 すべてのentry要素に続いて記事が追加される
「/ND/blog/entries/entry」というXQueryは、すべてのentry要素を示すために、追加した記事が複数の場所に格納されてしまいます。 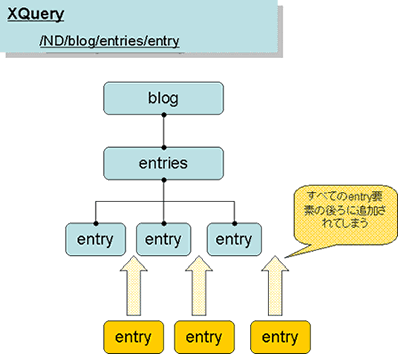
目的は新しい記事を1つ追加することですから,挿入ポイントとなる「entry要素」を1つに絞り込まねばなりません。
絞り込みには,先ほど紹介した述語を使います。新規記事はentry要素の最後に追加しますが,これに便利なのが「last()」という関数です。述語に last()関数を指定すると,該当する要素の最後を指すようになります。これを使った図10が正しいXQuery式になります。
図10:記事追加時のXQuery指定例述語部分にlast()関数を指定し、最後のentry要素であることを示しています。
| /ND/blog/entries/entry[last()] |
このXQuery式を使って、新規のXMLデータをXprioriデータベースに追加するPerlプログラムのサンプルを図11に挙げました。データの挿入ポイントをXQuery式で指定し、insertXMLメソッドでデータを追加しています。
図11:XMLデータの追加プログラムの例Perlを使った場合の例です。XQuery式でデータの挿入ポイントを指定し、insertXMLメソッドでデータを挿入しています。
#!/usr/bin/perl -w
use NeoProxy; # HTTP API Perl implementation
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
#Xprioriにログイン
$result = $my_proxy->login("Administrator", "admin");
#記事の内容をXML化する
$xml_string = "<entry><title>タイトル<\/><contents>コンテンツ<\/contents><trackback>trackback<\/trackback>
<\/entry>
#挿入ポイントをXQuery式で指定
$xpath = "/ND/blog/entries/entry[last()]";
#クエリを実行
$query_result = $my_proxy->insertXML($xpath,$xml_string);
$result = $my_proxy->logout($query_result);
print $query_result; |
図11のプログラムの実行結果が図12です。
図12:XMLデータ追加時の実行結果Insert-Nodes要素に、XMLデータを追加した場所の数が示されています。
<?xml version="1.0" encoding="utf-8" ?> <Insert-Results> <Insert-Nodes>1</Insert-Nodes> </Insert-Results> |
先に説明したように、挿入ポイントを指定するXQuery式は複数の要素を指すこともあります。実際にいくつの要素のあとにXMLデータを挿入したかは、実行結果の「Insert-Nodes」要素に示されています。
これで記事追加用のCGIプログラムを作成できます。CGIプログラムは記事入力用のフォーム(写真2)を備え,入力された文字列にタグ付けする機能を提供します。
写真2 記事入力用のフォーム 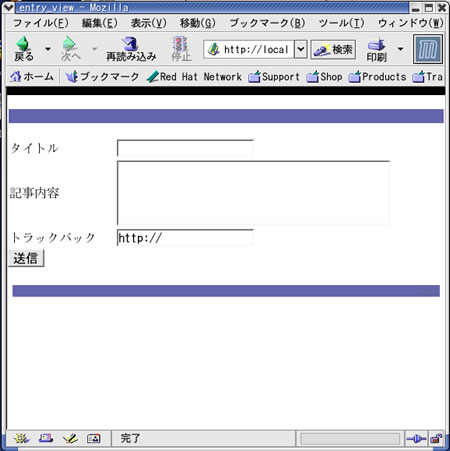
主な部分のプログラム・コードを図13に挙げました。このCGIプログラムを使った記事追加の様子が写真3です。
図13:記事追加用のCGIプログラム一部だけを抜き出しています。完全なプログラムは本誌Webページで「add_entry.cgi」という名前で配布しています。
#記事の内容を受け取る
$title = $q_cgi->param('title');
$entry_contents = $q_cgi->param('entry_contents');
$trackback = $q_cgi->param('trackback');
#記事の内容をXML化する
$xml_string = "<entry><title>$title<\/title><contents>$entry_contents<\/contents><trackback>trackback
<\/trackback><\/entry>";
#挿入ポイントのXPathを作成
$xpath = "/ND/blog/entries/entry[last()]";
#クエリを実行
$query_result = $my_proxy-<insertXML($xpath,$xml_string);
$result = $my_proxy-<logout($query_result); |
写真3 記事追加時のWebブラウザの表示例 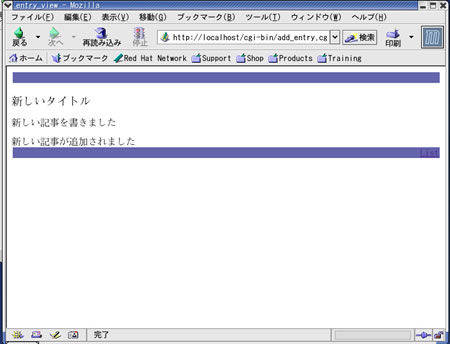
登録記事の編集/削除
次に記事を編集する方法を紹介しましょう。記事の編集は,要素中のXMLデータを変更する作業に対応します。Xprioriでは,要素中のXMLデータを変更するメソッドとして「modifyXML」を用意しています。このメソッドは,1つ目の引数に変更対象の要素を示すXQuery式,2つ目の引数に変更後のXMLデータを指定します。
例えば,1番目の記事のタイトルを変更する場合は,XQuery式として「/ND /blog/entries/entry[1]/title」を指定します。変更後のXMLデータ(2つ目の引数)は「<title>タイトルを変更</title>」というように,要素の内容だけでなく要素名(タグ)も記述する必要があります。
図14に記事のタイトルを更新するプログラムのサンプルを挙げました。その実行結果の例が図15です。
図14:記事タイトル更新用のCGIプログラムmodifyXMLメソッドを使ってtitle要素を更新するCGIプログラムです。
#!/usr/bin/perl -w
use NeoProxy; # HTTP API Perl implementation
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
#Xprioriにログイン
$result = $my_proxy->login("Administrator", "admin");
#変更内容
$xml_string = "<title>タイトルを変更<\/title>";
#挿入ポイントのXPathを作成
$xpath = "/ND/blog/entries/entry[1]/title";
#クエリを実行
$query_result = $my_proxy->modifyXML($xpath,$xml_string);
print "------------更新結果-----------\n";
print "$query_result\n";
#結果を確認する
$query_result = $my_proxy->queryXML("/ND/blog/entries/entry");
print "------------確認結果-----------\n";
print "$query_result\n";
$result = $my_proxy->logout($query_result); |
図15:記事タイトルの更新結果
Modified-Nodes要素に更新した記事の番号が格納されています。タイトルも更新されています。
------------更新結果-----------
<?xml version="1.0" encoding="utf-8" ?>
<Modify-Results>
<Modified-Nodes>1</Modified-Nodes>
<Matching-Nodes>0</Matching-Nodes>
</Modify-Results>
------------確認結果-----------
<?xml version="1.0" encoding="utf-8" ?>
<Query-Results>
<entry>
<title>タイトルを変更</title>
<contents>絶対反対です!(-_-;)</contents>
<trackback>trackback</trackback>
<date>2004-08-06</date>
</entry>
<entry>
<title>今日も負けた。。。</title>
<contents>4連敗です。。。ちょっと前に6連勝したのに台無し。今年は異常に巨人に弱いのが気になる
</contents>
<trackback>trackback</trackback>
<date>2004-08-04</date>
</entry>
<entry>
<title>アニキ!</title>
<contents>ついに日本記録達成ですね!おめでとうございます。次は世界を目指して・・・
</contents>
<trackback>trackback</trackback>
<date>2004-08-01</date>
</entry>
</Query-Results> |
最後に記事を削除する方法を紹介します。記事を削除するには「entry要素」を削除します。これにはXprioriの「deleteXML」メソッドが利用できます。同メソッドは,引数のXQuery式で指定された要素を削除します。例えば,最後に追加した記事を削除するには,XQuery式として「/ND/blog/entries/entry[last()]」を指定します。
図16に記事を削除するプログラムのサンプルを挙げました。その実行結果の例が図17です。
図16:記事削除用のCGIプログラムdeleteXMLメソッドを使ってentry要素を削除するCGIプログラムです。
#!/usr/bin/perl -w
use NeoProxy; # HTTP API Perl implementation
my $my_proxy = new NeoProxy();
my $result = new NeoResult;
#Xprioriにログイン
$result = $my_proxy->login("Administrator", "admin");
#挿入ポイントのXPathを作成
$xpath = "/ND/blog/entries/entry[last()]";
#クエリを実行
$query_result = $my_proxy->deleteXML($xpath);
print "$query_result\n";
$result = $my_proxy->logout($query_result); |
図17:記事の削除結果
Deleted-Nodes要素に削除した記事の数が格納されています。
<?xml version="1.0" encoding="utf-8" ?>
<Delete-Results>
<Deleted-Nodes>1</Deleted-Nodes>
</Delete-Results> |
ここまでの説明で,Blog記事の検索,追加,更新,削除といった機能を実装できるようになりました。XMLデータベースの操作において,XQueryが重要なポイントになることがご理解いただけたと思います。ぜひ使い方を体得して,自在にXMLデータベースを使いこなせるようにしてください。
なおBlogサイトとしては,これまでに紹介した機能だけでは不十分です。例えば,トラックバック・ピンの送受信機能や,コメントの入力機能なども必要でしょう。しかし本連載のようにXMLデータベースを採用していれば,これらの機能追加の際にも,データベース設計を見直す必要はありません。自由にデータベースに項目を追加できます。そのため,プログラム開発は極めて容易です。必要な情報はすべて3回の連載中で示していますから,ご自分でさまざまな機能拡張を施してみてください。
XMLやXMLデータベースと聞くと難しい印象がありますので「食わず嫌い」な方も多いと思います。しかし実際は,極めて柔軟で使いやすいデータベースです。本連載を機会に,XMLやXMLデータベースに親しんでいただければ幸いです。
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
