NeoCoreXMS徹底解剖 1. Quick Solution
※この記事はDigital Xpress 2004 Vol.20(4-5月号)に掲載されたものです。


はじめに
第一部で概観することができたように,NeoCoreXMS はユニークなテクノロジを背景に持ち,突き抜けたパフォーマンスを提供してくれる。
加えて,ユーザインターフェイスなどの機能が徹底してそぎ落とされており,製品として非常に軽く,また,黒子に徹することができるように配慮されていることにも,注目することができるだろう。これは決してデメリットではなく,様々なソリューションやワークフローの中に組み込める柔軟性を意味するメリットだと認識するほうが正解だろう。
実際,既に NeoCoreXMS を核としたソリューションがいくつも発表されており,いわゆるNeoCore陣営は様々なニーズに対して死角がなくなりつつある。
この第二部ではその既存ソリューションの中から代表的な幾つかのものをピックアップし,ご紹介する。
1.Quick Solution
最初にご紹介するのは,住友電気工業株式会社/住友電工情報システム株式会社が提供する,類似情報検索エンジン「QuickSolution」である。
「QuickSolution」はXML 対応の自然文検索エンジンで,検索のための辞書が不要であり,製品名,型番,社名,地名等の固有名詞や新語,および口語的表現等を含む文書を自然文により効率よく検索できるソリューションを提供する。たとえ入力した質問文と検索対象の文章が完全一致していなくても,キーワードを抽出し,類似するドキュメントを検索できるようになっている。
従来はこのような自然語検索の場合,いわゆる「ごみ」と呼ばれる,ミスマッチな検索結果を得ることが多かったのだが,「QuickSolution」は独自のアルゴリズムで自然語の中からジャストフィットするキーワードを抽出することができるよう,工夫が施されている。(図1 参照)
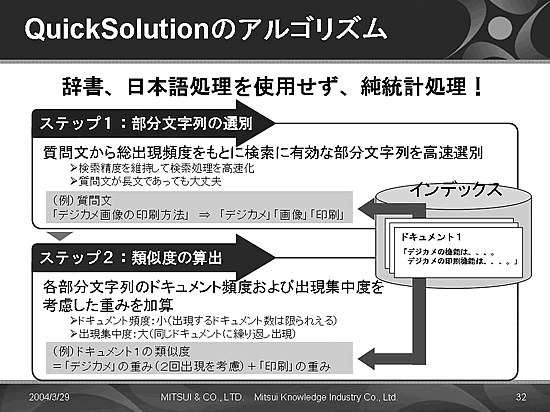
図1:QuickSolutionのアルゴリズム
製品の特徴
製品の主な特徴としては,以下のものが挙げられる。
- 自然文検索により類似検索(概念検索)が可能
- N-gram 方式による漏れのない検索
- 英語 / 中国語等,マルチリンガル対応
- 高速な検索(10GB のテキストを0.1 秒で類似検索可能)
- 組込み / インテグレーションが容易
- Javaで実装,プラットフォームを選ばない
- キーワード抽出 / クラスタリング等,テキストマイニング機能をサポート
対応しているデータベース/データ形式も幅広く,CSV やテキストファイルから,文書ファイル(Word, Excel,PowerPoint,PDF,一太郎,HTML),RDB のデータ(Oracle,DB2,SQL Server,Access),NeoCoreをはじめとしたネイティブXMLデータベース(eXcelon,Yggdrasill),Lotus Notes と多岐に渡っている。また,ここに挙げられていない形式に対しても,データリーダを追加することにより対応可能であるとのことだ。
既に事例として導入された事例も多く,一般的な情報検索サイトだけでなく,様々なポータルサイトにおける活用がなされている。最近では,ナレッジポータルや部門内ポータルへの注目が高まっているが,「QuickSolution」を導入することにより,XMLで柔軟に管理されているデータに対して自然語で検索し,目的のデータを探し当てるといった,有機的でクリエイ ティブな環境を構築することができる。
幾つか代表的な機能を取り上げてその優位性を検証してみよう。
検索機能
「QuickSolution」の根幹をなす部分だけに,多くのテクノロジが注ぎ込まれている。ユーザは最大の特徴である類似検索(自然文による類似ドキュメントの検索,あいまい検索,概念検索)を行なうことができるし,より絞り込んで効率よく作業を行なうためにキーワード検索(キーワードを指定して全文検索)やXMLの属性をキーにした検索(Enum 型,数値型,日付型等のフィールド検索)を行なうことができる。
検索を指示するインターフェイスは自由にカスタマイズすることができる。
統合検索機能
昨今多く見られる分散型の環境においても「QuickSolution」を使用して,柔軟な検索を行なうことができるようになっている。
その場合,「QuickSolution」は以下の3つのものから最適な検索方法を選択することができるようになっている。
- 横断検索:種類や構造の異なる複数DBの横断検索
- 仮想DB検索:複数DBを結合して検索
- 分散検索:複数サーバ間の協調による分散検索
キーワード抽出機能
辞書を使用した固定的なものではなく,純粋に統計処理(文字列の出現頻度,出現集中度)を用いたアルゴリズムによりキーワードを抽出することにより,新語・複合語にも対応することが可能になっている。
クラスタリング機能(オプション)
蓄積されたドキュメント群(Q&Aデータ,アンケート等)を類似度をもとに分類し,グループ分け(クラスタリング)することができる。また,クラスタリングしたグループごとに典型的な代表ドキュメントを選出し,例えば,蓄積された生のQ&AデータからFAQ(Frequently Asked Questions)を作成するといったことができるようになる。
NeoCoreXMSとの連携
「QuickSolution」がターゲットとしている文章系の半定型なデータを処理する上で,NeoCoreXMSの柔軟性と高速性はベストマッチの機能を提供している。両者を組み合わせることにより,ある程度XMLの構造や属性を考慮に入れて,文章中のキーワードで高速に検索したり,表現のゆれを吸収して検索したりすることができるようになる。
「QuickSolution」はNeoCoreXMSに保持されているXMLデータや任意の要素/属性を検索対象として設定することができるだけでなく,要素/属性ごとに類似/キーワード/属性検索種別を指定することが可能である。
さらに,NeoCoreXMSを利用することで,属性インデックス領域の圧縮が可能であったり,ファイルに対する検索インデックスを作成することができたりと相性は抜群である。
XMLのメリットであるデータの再利用性のメリットをより享受するためにも,また,せっかく蓄積したデータを "宝の持ち腐れ" にしないためにも,「QuickSolution」は魅力的なソリューションを提供している。
お問い合わせ,資料請求,デモンストレーションのご希望はこちらまで
住友電工情報システム株式会社
東京 管理ソリューション開発部 営業企画グループ
〒107-0051 東京都港区元赤坂1-3-12(赤坂センタービル)
TEL:03-3423-5263 FAX:03-3423-5000
大阪 システム営業部 営業課
〒532-0004 大阪府大阪市淀川区西宮原2-1-3(SORA新大阪21ビル)
TEL:06-6394-6731 FAX:06-6394-6704
E-mail:qs-visitor@sei-info.co.jp
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
