トピック指向の次世代文書記述言語-DITA詳細解説2 ~ 活用方法と深層に迫る ~
3. トピックの構成
トピックは「タイトル+内容」という基本構成をしている。(図2)
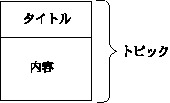
図2:トピックの基本構成
トピックには型(Type)がある。トピックの型を情報型(Information Type)という。DITAが定義しているオリジナルの型は次の4つである。
Concept型
Task型
Reference型
Glossary型
Concept型は「概念」を説明する際のトピックであり、Task型は「作業」を説明する型である。そしてReference型はコマンド一覧などの「参照資料」を記述するための型である。また、Glossary型は「用語集」を記述するための情報型であり、DITA 1.1から入ったものである。
DITAでは、特定の用途を意識したトピック型を新たに定義することもできる。これをトピック型の専門化(specification)という(「6. DITAのカスタマイズ」を参照)。
3.1 Concept型トピック
Concept型のトピックは、概念を説明する「解説書」タイプの技術資料を記述するためのものである。
たとえば、Concept型でトピックを記述すると、次のようになる。
<concept id="unikoro-history">
<title>ウニころがしの歴史</title>
<conbody>
<p>ウニころがしは、はるか千年前にウニの国で始まった慣習と関係がある。</p>
<p>ウニころがしを伝統的に使ってきたのは、次の民族である</p>
<ul>
<li>ウニ民族</li>
<li>ウメ民族</li>
</ul>
</conbody>
</concept>
<concept>はConcept型のトピックの始まりを示す。このタグには、必ずid属性がなければならない。このid値がトピックを識別するための記号となる。
<title>はトピックの表題を記述するためのものである。一つのトピックには、一つのtitle要素しか指定できない。
<conbody>の内容がトピックの具体的な中身である。いわば「本文」に相当する部分である。これも一つのトピックに一つしか記述できない。
この例はConcept型であるが、Task型やReference型の場合には、トピックや本文を開始する要素の名前が異なり、それぞれ<task>と<taskbody>、<reference>と<refbody>が使われる。(表1参照)
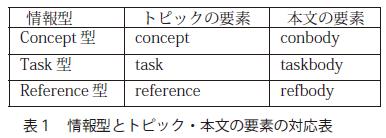
表1のように、トピックやトピックの本文に異なる名前を割り当てることにより、各要素に含めることのできる要素や属性を、情報型ごとに定義できるようになっている。
3.2 Task型トピック
Task型のトピックは、「作業手順書」などを記述するためのものである。したがって、作業内容や作業上の注意点、また作業の順番などの情報を記載できるようになっている。
Task型のトピックの本文(taskbody)には、次の要素を含めることが可能である。いずれの要素も必須ではない。
<prereq> 作業を始めるための前提条件
<context> 作業の予備知識(例、作業の目的や予想される結果などの簡潔な説明)
<steps> 作業手順
<result> 期待される成果
<example> 作業例など
<postreq> 作業が成功した場合の、次作業
Task型のトピックを例示すると、次のようになる。
<task id="unikoro-play1">
<title>ウニころがしの遊び方(1)</title>
<taskbody>
<prereq>ウニころがしで遊ぶ前には、よく手を洗うこと。</prereq>
<context>ウニころがしで手のマッサージをする。</context>
<steps>
<step>ボールをつかむように、片手で軽くつかむ</step>
<step>ウニころがしの電源を入れる</step>
</steps>
<result>ウニころがしの突起によるマッサージを楽しむ</result>
</taskbody>
</task>
Task型のトピックの場合、使える要素を固定することで、作業手順の書き方を標準化している点に注目できる。これにより、作業手順の書き方が執筆者によってまちまちにならないようにして、読みやすく、読者がより理解できるような資料を作成できる。また執筆者の間で、作業手順の明快な記述方法について共同の認識を持つこともできるのである。
3.3 Reference型トピック
Reference型は名前のとおり、「参考情報」や「参考資料」を記述するためのものである。コンピュータの世界であれば「コマンド一覧」や「API一覧」、製造の世界であれば「部品表」などがある。
Reference型トピックの本文を示すrefbody要素には、トピックの内容や形式を反映した、いくつかの特徴的な要素がある。
<section> トピックの見出しや下位のトピックのまとまりを示す。入れ子にできない
<refsyn> コマンドの構文やAPIの呼出し形式などを記述する
<example> トピックに関連した例を示す
<table> 表形式。セルを結合するなどの複雑な表を作成できる
<simpletable> 単純な表形式
<properties> プロパティリスト
たとえば、ウニころがしのライトを点滅させる間隔を秒数で指定する構文が、
Unikoro.blink = 点滅秒数
という形式であるなら、Reference型のトピックは次のようになる。
<reference id="unikoro-blink">
<title>ウニころがしのライトの点滅間隔の設定構文</title>
<refbody>
<refsyn>
<synph>
<var>Unikoro</var><delim>.</delim><kwd>blink</kwd>
<delim> = </delim><var>点滅秒数</var>
</synph>
</refsyn>
</refbody>
</reference>
<synph>は構文を示す要素である。<var>は変数を、<kwd>はキーワードを示す。<delim>は区切り文字である。複雑な構文の場合、XMLのタグをキーボードから直接入力するのはたいへんな作業になる。複雑なタグを駆使する場合は、入力支援ツールが必要になるだろう。
3.4 Glossary型トピック
Glossary型のトピックはDITA1.1から新たに導入されたもので、「用語集」を記述するためのトピックである。Glossary型のトピックは、一つの用語に付いて一つのトピックを作成する。トピックを示す要素はglossentryで、その中に用語を示すglosstermと、用語定義を示すglossdefを記述できる。
たとえば、「ウニ突起」という用語を定義すると、次のようになる。
<glossentry id="unikoro-tokki">
<glossterm>ウニ突起</glossterm>
<glossdef>ウニころがしの表面にある可動式の棒状のもの</glossdef>
</glossentry>
用語集のトピックは、対象となる製品や情報の範囲が広い場合、大量に存在することが考えられるので、データベースや他の管理手段によって効率的にトピックを管理しないと、混乱や間違いの誘因になる。
3.5 ドメインとその要素
トピックの主な構成要素について調べてきたが、実際にトピックを記述する場合は、文字列に修飾を加えて強調したり、索引項目を指定したりするなど、さまざまな要素を付加的に使用することになる。
このように特定の用途のための要素の集合を定義したものが、DITAのドメイン(domain)である。
DITA 1.1で提供しているドメインには、次のものがある。なお( )内はドメインの簡略表記である。
タイポグラフィック・ドメイン(hi-d)
文字列や用語を強調するための要素の集合。XMLの思想上、DITAでは意味を表す要素によって文字列や用語を指定するほうが望ましいが、適切な要素がない場合は、このドメインの要素を使用できる。
例:<i>(斜体)、<sup>(上付き文字)など
プログラミング・ドメイン(pr-d)
プログラミングやプログラム言語を記述するときに役立つ要素の集合。
例:<apiname>(API名)、<delim>(区切り文字)、<parml>(パラメーター・リスト)など
ソフトウェア・ドメイン(sw-d)
ソフトウェアについて記述するときに役立つ要素の集合。
例:<cmdname>(コマンド名)、<msgblock>(メッセージ)、<magnum>(メッセージ番号)、<userinput>(ユーザーの入力)など
ユーザー・インターフェイス・ドメイン(ui-d)
ユーザー・インターフェイスについて記述するときに役立つ要素の集合。
例:<screen>(画面)、wintitle(ウィンドウの表題)など
ユーティリティ・ドメイン(ut-d)
イメージマップなどの役立つ機能を使えるようにするための要素の集合。
例:<imagemap>(イメージマップ)、<coords>(座標)など
索引指定ドメイン(indexing-d)
索引指定機能を拡張するための要素の集合。DITA1.1の新機能である。
例:<index-see>(索引に、「~を参照」という項目を作成する)、<index-see-also>(索引に、「~も参照」という項目を作成する)、<index-sort-as>(索引のソートのキーを指定する)
このようにドメインに分類されている目的は、要素のモジュール化である。要素をモジュール化することで、DITAを規定するDTDやXML Schemaの構成をモジュール化できる。モジュール化が進んでいれば、モジュール単位で差し替えや拡張が可能になるからである。
3.6 トピックの全体構成
これまでは話をシンプルにするために、トピックの構造を「タイトル+本文」にしぼって説明してきたが、実際のDITAのトピックには、さらに多くの情報を加えることができる。
DITAのトピックの全体構成は図3のようになっている。
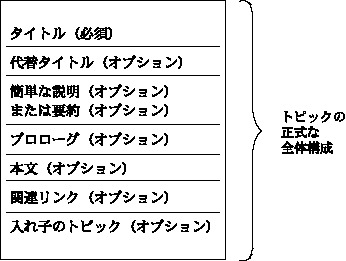
図3:トピックの全体構成
「タイトル」には、正式なタイトル(<title>)の後に、代替タイトル(<titlealts>)を記述することも可能である。代替タイトルはリンクのナビゲーションの際や検索のときに使用される。
「簡単な説明」や「要約」は、それぞれトピックについて説明するものであるが、「要約(<abstract>)」のほうが「簡単な説明(<shortdesc>)」より長くて詳しいものになる。リンク時の表示や要約の自動生成などで使用できる。
「プロローグ」はトピックに関連するメタデータを記述するためのものである。「プロローグ(<prolog>)」には、著作権情報(<copyright>)、変更履歴(<revised>)、対象読者(<audience>)、製品名(<prodname>)などを必要に応じて記載する。
「本文」はこれまで説明してきたとおりであるが、本文では一般的な文書を記述するための要素を使用できる。代表的なものをあげると、段落(<p>)、注(<note>)、相互参照(<xref>)、番号付きリスト(<ol>)、定義リスト(<dl>)、図(<fig>)などがある。また、表(<table>)や簡易表(<simple>)も作成できる。
「関連リンク」は他のトピックへのリンクをまとめたものである。<link>、<linklist>、<linkpool>、<linktext>、<linkinfo>というタグがある。しかし、トピックの関連を示すのに、この「関連リンク」を使うのか、後述するDITAマップを使うのかについては、トレードオフや利点・弱点の関係があるので、全体方針に基づいて判断しなければならない。
「入れ子のトピック」は、トピックの中にトピックを記述するためのものである。入れ子にするなら、文書構造は当然、複雑になる。「関連リンク」と同様、注意して使うべきである。
トピックを構成する主な項目の中で、必須なのは「タイトル(<title>)」だけである。つまり、本文がなくても、タイトルだけがあれば、文法上はトピックとして成り立つのである。あとの項目はオプションになっている。もちろん、ほとんどの場合、本文がなければトピックとして用を成さないだろうことは容易に推測できる。
トピックで使用できる標準的な要素は、必要に応じて新たなドメインを作成して要素を追加する場合の基礎となるものである。この点については、「6. DITAのカスタマイズ」で説明する。
3.7 conref属性とトランスクルージョン
DITAの要素では、idだけでなく、他にもさまざまな属性が使用できるようになっている。その中で、DITAにとって特徴的なのはconref属性である。
conrefは「内容(content)を参照(reference)する」機能である。たとえば、①の記述で、②の内容を参照するとしよう。
......
<note conref="#unikoro-note1">注1参照</note> ←①
①の例はconref属性で②の要素を参照しているので、DITA文書を処理する際に、①の「注1参照」という内容は②の「ウニころがしは水気をきらいます」という内容に置き換えられる。
conref属性を持つ要素は「参照先の内容が置かれる位置」を示しており、置換後は、conref属性を持つ要素に含まれていた内容は無視される。これはXMLのXIncludeと同種の機能である。conref属性で実現される機能をトランスクルージョン(transclusion) という。
技術文書では、同じ注記や同一の表現を繰り返し用いる場合があるが、その都度記載するなら、内容に変更が加わったときに、出現箇所すべてを修正しなければならなくなる。これは修正ミスを誘発するだけでなく、手間のかかる作業でもある。conref属性によるトランスクルージョン機能を上手に使っていれば、修正箇所は一箇所ですむはずである。
同時に、conref属性による参照は、トピック間およびトピック内の要素間の参照関係を複雑にする要因にもなるので注意深い使用が求められる。
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
