トピック指向の次世代文書記述言語-DITA詳細解説3 ~ 活用方法と深層に迫る ~
4. マップの構成
DITAマップは、細分化されたトピックをひとまとめにする役割を持っている。いわばトピックの「目次」のようなものである。
DITAマップを識別するタグは<map>である。その要素の中で、トピックを参照する<topicref>を使用して、マップを構成するトピックの順番や構造を指定する。
<map id="unikoro-help">
<title>ウニころがしの使い方</title>
<topicref href="uni-hisotry.dita" type="concept" ></topicref>
<topicref href="uni-play1.dita" type="task" ></topicref>
<topicref href="uni-blink.dita" type="reference" ></topicref>
</map>
この例では、3つのトピックが順番に並んでいる。トピックの型はtype属性で指定できる。
DITAのマップで表現できるトピックの構造には、次の3つの種類がある。
階層構造
表構造
グループ
階層構造は、<topicref>の順序や入れ子によって示される。<topicref>要素の入れ子構造および出現順がトピックの構造を表している。これはXMLの要素の木構造を利用したものであり、各トピックの関係には、親子、兄弟などがある。
たとえば、<topicref>の次の並びを考えよう。
<map id="map1">
<topicref href="A.dita" >
<topicref href="B1.dita" ></topicref>
<topicref href="B2.dita" ></topicref>
</topicref>
</map>
この階層構造を図示すると、図4のようになる。各トピックの関係は双方向であることに注意したい。特に指定しないがきり、<tiopicref>間のリンクは相互にはられる。
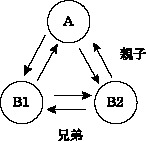
図4:トピックの階層構造
リンクを一方向のみ有効にしたい場合は、
たとえば、B2.ditaを指定する<topicref>にlinking="sourceonly"があると、それが指定されたtopicrefを起点とするリンクだけが有効になる。(図5)
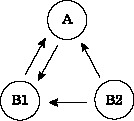
図5:source only の場合のリンク構造
<map id="map2">
<topicref href="A.dita" >
<topicref href="B1.dita" ></topicref>
<topicref href="B2.dita" linking="sourceonly"></topicref>
</topicref>
</map>
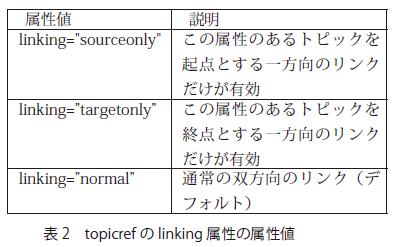
表構造は関係表(<reltable>)で表され、表の各行に含まれるセルの関係を表している。したがって、関係表では各セルに含まれるトピック相互の関係は表現しない。また、セルの中で各行は独立しており、その中の行と行の関係を表現することもない。ただし、関係表には、見出し行(<relheader>)を付けることができ、それは各行に含まれるセルの意味を説明するのに役立つ。
<map id="map3">
<reltable>
<relrow>
<relcell><topicref href="A.dita" ></topicref></relcell>
<relcell>
<topicref href="B1.dita" ></topicref>
<topicref href="B2.dita" ></topicref>
</relcell>
</relrow>
</reltable>
</map>
これを表にすると次のようになり、リンクの関係を図示すると、図6のようになる。

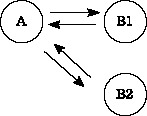
図6:関係表を使ったリンク構造
topicrefの階層構造によるトピックの関係記述と、reltableの関係表による記述の両方を、同じマップの中で同時に使用することができる。
一方、グループ(<topicgroup>)は、構造とは無関係な集まりを定義するために使用する。この<topicgroup>は独自のidを持てるので、いつかのトピックをまとめて管理したり、また共通の属性を持つようにまとめたりするのに使用できる。
<topicgroup id="grp10">
<topicref href="uni-hisotry.dita" type="concept" ></topicref>
<topicref href="uni-play1.dita" type="task" ></topicref>
<topicref href="uni-blink.dita" type="reference" ></topicref>
</topicgroup>
DITA 1.1からは、書籍用の機能を備えたBookMapが標準化されている。
5. DITAの運用
では、DITA文書は技術文書の制作工程においてどのように使用されるのだろうか。
技術文書の利用媒体には、伝統的な印刷物、PDFによる電子書籍、HTMLによるWeb配信、ヘルプの製品への組み込みなど、さまざまなものがある。
XMLやSGMLの効用として従来から「ワンソース・マルチユース」ということが主張されてきたが、これを理念ではなく実践してみると、「ワンソース」の中に出力媒体に関する情報を組み込まざるをえないという現実に直面していた。これではかえって「ワンソース」の内容が複雑になってしまう。理念はシンプルを目指しているにも関わらず、実践は複雑になるのである。この矛盾を解消するため、DITAは「ワンソース」の中で出力媒体に関する情報を「マップ」として切り出したのである。
DITAを使った媒体ごとの配布物の主な制作工程は、図7のような形になる。
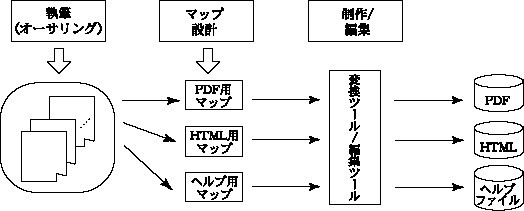
図7:DITAを使った主な制作工程
また、DITAに対応している主な製品やツールは表3のとおりである。

代表的なものだけあげたが、ほかにもDITA対応の製品やツールは登場してきており、これからが楽しみである。
6. DITAのカスタマイズ
DITAのDはDarwinの頭文字であり、DITAには「専門化」と「継承」により発展性があることを意味していることは最初に述べたとおりである。では、「専門化」や「継承」とは何であろうか。またそれによりDITAはどのようにカスタマイズ可能なのだろうか。
DITAの専門化(specialization)とは、DITAの持つ標準的なタグセットを拡張して新たに定義することである。DITAの専門化には、二種類のレベルがある。一つはトピックレベルでの専門化であり、これを「情報型の専門化」という。もう一つは要素レベルでの専門化であり、「ドメインの専門化」という。
情報型の専門化は、DITA 1.1が標準で提供しているConcept型・Task型・Reference型・Glossary型以外の、新しいトピックの型を定義することである。
企業や団体の作成する文書の内容によっては、DITAが標準で提供する区分だけでは対応しきれないこともある。ユーザーにあった情報型を定義して、専用のトピックを用意したほうが、執筆やトピック管理が容易になることもある。そうした場合には、DITAをカスタマイズして、新しい情報型を作成したほうがよいだろう。その場合は、既存の情報型や一般的な(generic)トピック型(topic)から派生する形で新しいトピックの情報型を定義する。
一方、ドメインの専門化は、トピック以下の要素について、DITAの標準的な要素セットを拡張して新たに定義することである。専門化によって作られる拡張要素のセットが「ドメイン」であるが、これはすでに3.5で説明したドメインと同じである。
専門化は、元になる要素から結果となる要素を派生させることなので、結果となる要素は元になる要素から性質を「継承」することになる。これはオブジェクト指向の手法を適用したものである。
たとえば、ユーザー・インターフェイス・ドメイン(ui-d)の専門化において、そのドメインに含まれる要素と派生元との関係を表4に示す。
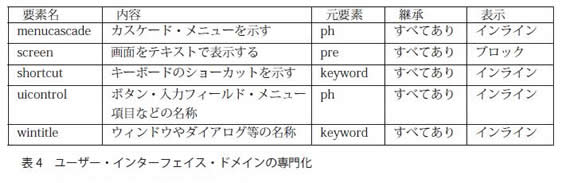
専門化は抽象レベルのものであり、その実装は既存のDTDやXMLSchemaの変更や追加の形で行われる。DTDやXMLSchemaにおいて専門化の鍵を握るのは、class属性である。たとえば、ui-dドメインのshortcut要素のclass属性は固定値でkeywordになっている。DITAの処理系はclass属性を見てその要素の振る舞いの継承を判断する。執筆時に、class属性を変更することは厳禁である。
DITAのカスタマイズは、処理系との整合性が取れていなければならない。トピックの中に埋め込まれる情報が処理上どのような意味を持つかは、処理系の処理や操作の仕方に依存しているからである。
DTDやXMLSchemaをカスタマイズするには、DTDあるいはXMLSchemaについての高度な技術が必要になる。DITAでは、パラメータエンティティの活用など、専門化のための手法が決められているので、その規約にしたがってDTDやXMLSchemaに修正を追加する必要がある。
7. コンテンツ作成の方法論とDITAの意義
DITAを採用することには、単に文書の形式を決める以上の意味がある。既存文書の内容的な構造を「トピック」という比較的小さな情報の固まりに、関係性を保ちながら構成することを意味するからである。つまりDITAを選択することは、トピック指向というコンテンツ作成の方法論を選択することである。
情報をどのように管理して分かりやすく提供するかについては、これまでさまざまな議論がなされてきたが、注目できる一つの流れはミニマリズム(Minimalism)である。
ミニマリズムは建築・音楽・芸術の分野で1960年前後に現れた流れで「最小限」を特徴とする。情報の世界においても、1998年にJohn M. Carrollが編集したMinimalism Beyond the Nurnberg Funnelという書籍がMIT Pressから出版された。コンピュータやソフトウェアの操作を覚えるのに、とても読みきれない情報を提供するよりも、「最小限」の情報を提供して、実地で作業を体験して覚えるような方向性が現れたのである。
こうした技術情報におけるミニマリズムの流れに、DITAは親和性がある。意味を成す最小単位に作られたトピック、トピックの柔軟な組み合わせによるコンテンツの開発など、技術情報の再利用と効率的な構成をDITAは可能にしているからである。
DITAはアーキテクチャーである。DITAは、技術文書の執筆から制作までの工程を省力化し、将来登場すると思われる新たな媒体や形式に柔軟に対応していくのに有効なプラットホームとなりうる。DITAは特定の会社の固有の形式ではない。標準仕様としてだれもが自由に使え、コミュニティにより発展していく仕様である。DITAは技術文書の分野において、WebサイトにおけるHTMLのような位置づけになる可能性を持っている。こうした点を考えると、DITAによる技術文書の蓄積は、検討可能な有効な手法であるといえるだろう。
参考文献・サイト
DITA Version 1.1 Architectural Specification
DITA Version 1.1 Language Specification
CoverPages: Darwin Information Typing Architecture (DITA XML)
(http://xml.coverpages.org/dita.html)
「Darwin Information Typing Architectureの紹介」
(http://www.ibm.com/developerworks/jp/xml/library/x-dita1-index/)
1.OASISの正式名称はOrganization for the Advancement of Structured Information Standardsであり、「グローバルな情報社会のオープン標準を開発、統合および採用を推進する非営利国際コンソーシアム」(httip://www.oasis-open.org/jp/を参照)である。文書、電子商取引、Webサービスなど、様々な分野のXML応用技術の標準化を推進している。
2.「専門化」も「分化」も英語は同じspecificationである。同様に、「継承」も「遺伝」もinheritanceである。英語の文化圏では、この2つの特徴からDarwinを連想するのは容易かもしれないが、日本語で考えるとそれは難しい。
3.たとえば、DITAの関連技術には、DocBook、Topic Maps、Information Mapping、Architectural Forms、XML Includesなどがある。
4.トランスクルージョンは、「ハイパーテキスト」という用語を生み出した米国のテッド・ネルソン(Theodore Holm Nelson)の作り出した概念である。リンクのように他の文書へ移動するのではなく、当該文書のとどまりながら参照先の文書の内容を「引用」して見るというものである。「窓による引用」ともいえる。
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
