グローバルな情報展開と翻訳関連データの標準化(2)
2. 翻訳関連データの標準化
日本ではあまり知られていないが、LISAという国際団体がある(www.lisa.org)。
LISA(リサ)はThe Localization Industry Standards Associationの頭文字をとった略称で、ローカリゼーション業界の国際的な標準化団体である。会員企業には、IBM、Hewlett- Packard、Cisco Systems、SAP、Adobe Systemsなどの製品やサービスをグローバルに展開している企業、LionBridge TechnologiesやSDL Internationalなどのローカリゼーションを業務とする企業、翻訳支援ツールなどのソフトウェア開発企業(SDLのTRADOSなど)、大学や他の標準化団体(OASISなど)がいる。
LISAのホームページによれば、ローカリゼーションのサービス提供者であるベンダーが47%、サービスを受けるクライアントが53%で、ほぼ半数ずつの構成になっている。本部はスイス にある。
LISAはグローバリゼーション/ローカリゼーションの市場調査・動向調査の出版、コンファレンスやセミナーの開催など、ヨーロッパを中心に多彩な活動をしているが、それだけでなく、LISAの名称にあるようにローカリゼーションに関連する標準化活動を行っている。それを実施しているのがLISAの標準化委員会のOSCAR(Open Standards for Container/content Allowing Reuse)である。
OSCARの標準規格には次のものがある。いずれもXMLをベースにした規格である。
Translation Memory eXchange(TMX)
Segmentation Rules eXchange(SRX)
Term-Base eXchange(TBX)
XML Text Memory(xml:tm)
Global Information Management Metrics eXchange-Volume(GMX-V)
Term-Link
まず基本的な要素である最初の3つの規格について考えよう。簡単にいうと、TMXは翻訳メモリの交換規格、SRMはセグメンテーション規則の交換規格、TBXは用語データの交換規格である。
「翻訳メモリ」とは、翻訳の原文と訳文を対応させた対の情報である。最近では、翻訳作業は翻訳支援ツールを使用して行われることがほとんどである。代表的な翻訳支援ツールには、SDL社のTRADOS、オープンソースのXLIFFなどがある。XLIFFの画面(図3)からわかるように、翻訳支援ツールの画面は翻訳対象の原文のウィンドウと訳文を入力するウィンドウに分かれている。
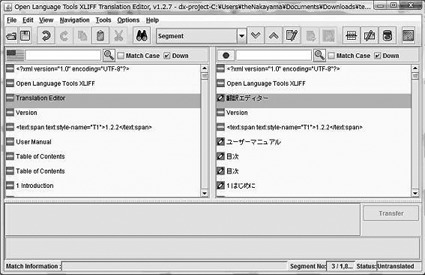
図3:XLIFFエディターの画面例
原文は「セグメント」と呼ばれる単位に分割されて管理されるので、原文をセグメントに分割するための規則が必要になる。それが「セグメンテーション規則」である。
翻訳支援ツールでは、翻訳対象部分に出現する用語が別ウィンドウに表示されることが多く、そのウィンドウから訳文の中に簡単に挿入できるようになっている。これは翻訳の品質と生産性を向上させるのに役立つ。このデータが「用語データ」である。
翻訳工程の中に、翻訳支援ツールおよびこれらの標準化されたデータを位置づけると、図4のようになる。
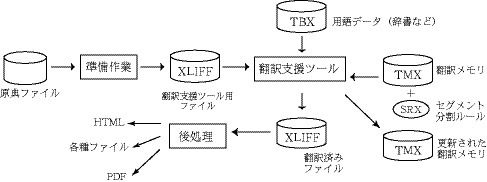
図4:翻訳工程と標準化されたデータ
これから、各規格の内容を具体的に概観することにする。
2.1 Translation Memory eXchange(TMX)
翻訳メモリは、文の単位を基本とするセグメントの集合であることはすでに説明した。翻訳支援ツールは翻訳メモリを内部的に固有の形式で保持している。TMXはXMLを使って、翻訳メモリを標準的な形式でエキスポートして、交換・保存するための規格である。
TMX の構造は比較的シンプルである。ルート要素は<tmx>であるが、大きな構造はHTMLと似ており、その後に<header>と<body>が続く。これらの構造要素をtmxのコンテナ(Container)という。
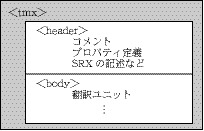
図5:tmxコンテナの構造
<header>の中には、任意のコメント(<note>)、メタデータとなるプロパティの定義(<prop>) 、セグメントの中にタグや特殊文字がある場合に翻訳箇所を整理するためのインラインデータの定義(<inline-data>) 、セグメントの分割規則であるSRXデータの記述(<segmentation>)を含めることができる。
<body.>は翻訳メモリの本体部分である。翻訳メモリの基本単位を翻訳ユニット(translation unit)といい、<tu>というタグで示す。TMXの翻訳メモリは文脈を伴うものではなく、基本的に原文と訳文のペアであるため、<tu>の並び順に意味はない。各翻訳ユニットは独立しており、それゆえに一つのマニュアルの中で同じ文章が反復される場合、翻訳メモリを使用すれば実質的な翻訳対象個所を減らすことができる。また、あるシリーズの翻訳メモリを蓄積していけば、同じシリーズに属する新規のマニュアルを翻訳するときに、同様の文章があればやはり翻訳対象個所を減らすことができる。
しかし、文脈に依存しない文章はないので、文脈から独立した翻訳メモリに頼り過ぎると、誤訳を誘発したり、同じような表現が繰り返されて単調で流れの悪い文章になったりして、翻訳文の品質が下がる可能性がある。この改善を図るために、翻訳メモリに文脈という要素を加えた規格が、後述するXMLテキストメモリ(xml:tm)である。
翻訳ユニットに話を戻すと、各翻訳ユニットには原文およびそれに対応する訳文を示す要素がある。これらをすべて翻訳ユニットバリアント(Translation Unit Varibant; <tuv>)という。1つの<tu>には、少なくとも2つの<tuv>がある。次に例を示す。
<tu>
<tuv xml:lang="ja" >
<seg>吾輩は猫である。</seg>
</tuv>
<tu xml:lang="en">
<seg>I am a cat.</seg>
</tuv>
</tu>
<tuv>の中に、原文および翻訳対象となるセグメント<seg>が入っている。<tuv>には他にもコメント<note>やプロパティ<prop>を含めることができる。1つの<tuv>に1つの<seg>しか含めることができない。
注意しなければならないのは、TMXはあくまで翻訳メモリつまり訳文データベースであるという点である。翻訳支援ツールの入力となる、翻訳対象の原典を記述したデータではない。原典データの標準規格には、XML規格の標準化団体であるOASIS が規定したXLIFF(XML Localization Interchange File Format)がある。XLIFFについては後述する。
2.2 Segmentation Rules eXchange(SRX)
SRX は翻訳対象となる原典を基本的に文の単位に分割する規則を交換するための規格である。分割されたものをセグメント(segment)という。
すでにTMXの項で言及したように、SRXはTMXを補完して、翻訳メモリの交換の際にセグメント分割規則の情報を添付することで、翻訳支援ツールなどのアプリケーションによる処理の差異をなくそうという意図がある。
SRXで定義するのは、基本的に次の2つの点である。
言語ごとの分割ルールの記述(<languagerules>)
分割ルールと言語IDと対応付け(<maprules>)
<languagerules>は、言語ごとの分割ルール(<languagerule>)の集合である。そして、各<languagerule>には、個別の<rule>が定義される(図6)。
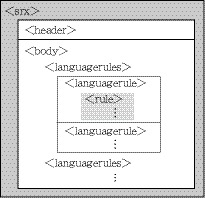
図6:SRXの分割ルールの構造
ルールにはセグメントの分割位置を、いわゆる正規表現(Regular Expression)を使ってパターンとして記述する。そのパターンに合致する場所がセグメントの分割位置である。
RXの正規表現で使用できる演算子や、メタ文字は次のとおりである。
メタ文字:¥a ¥A ¥b ¥B ¥cX ¥d ¥D ¥e ¥E ¥f¥G ¥n ¥N{ユニコード文字名} ¥p{ユニコードプロパティ名} ¥P{ユニコードプロパティ名} ¥Q ¥r ¥s ¥S ¥t ¥uhhh ¥Uhhhhhhh ¥w ¥W ¥x{hhhh} ¥xhh ¥X ¥Z ¥z ¥Onnn ¥n[パターン].^$¥
演算子:1* + ? {n} {n,} {n,m}
*? +? ?? {n}? {n,}? {n,m}?
*+ ++ ?+ {n}+ {n,}+ {n,m}+
例として、英語で"Mr."という文字列があった場合に、その直後でセグメントを分割してはならないが、そのパターンは、「¥sMr¥.」という式で表現できる。「Mr.」の次にはスペースが続くので、Mr.という文字列の後でセグメントの分割が生じないようにするルール(<rule>)は次のように記述できる。
<rule break="no">
<beforebreak>¥sMr¥.</beforebreak>
<afterbreak>¥s</afterbreak>
</rule>
エスケープ文字とメタ文字、また演算子を有効に活用して、さまざまな文字列のパターンを指定できる。この項の目的はSRXを概観することなので概要にとどめるが、SRXの基本は、正規表現による分割位置または分割抑止位置の指定、言語ごとのルールの定義、言語の識別子とルールのマッピング、デフォルトの分割ルールの指定などにある。
2.3 Term-Base eXchange(TBX)
TBX(Term-Base eXchange)はLISAの標準規格であるだけでなく、2008年にISO標準(ISO 30042)にもなった用語(terminology)データの交換規格である。TBXは用語集をXMLで記述するためのフレームワークを提供している。TBXはTML(Terminological Markup Language)という用語記述言語を定義する機能を持っている。TBXをベースとして、ジャンルの異なる用語集や用語データベースを構築できる。TBXに基づいて作成される用語集をTBXインスタンス文書(TBX instance document)という。
TBXの構成はモジュール構造をしている。TBXの中核をなし、TBXで使用できる要素と属性を定義する文書スキーマ(DTD)をコア構造モジュール(core-structure module)という。それに対してTBXで使用するデータカテゴリとその制約条件を定義するものを拡張制約指定(eXtensible Constraint Specification)という。TBXでは、コアとXCSのモジュール の組み合わせで一つのTMLを規定する(図7)。
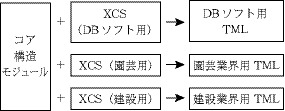
図7:TBXのコア構造モジュールとXCSによるTMLの定義
具体的な例を示してイメージをつかむことにする。
<langSet xml:lang="en">
<tig>
<term>piano</term>
<termNote type="partOfSpeech">noun</termNote>
<descrip type="context">I can play the piano.</descrip>
</tig>
</langSet>
<langSet xml:lang="ja">
<tig>
<term>ピアノ</term>
<termNote type="partOfSpeech">noun</termNote>
<descrip type="context">私はピアノを弾けます。</descrip>
</tig>
</langSet>
</termEntry>
この例では、英語の「piano」と日本語の「ピアノ」が用語として対応しており、品詞は名詞で、用例もある。<termEntry>が用語の項目を指定する要素、<langSet>が言語ごとの用語を識別する要素である。各言語での用語の詳細は用語情報グループ(Term Information Group)を示す<tig>要素の中に記述される。このレベルでの用語情報が複合的である場合は、<ntig>要素を使用する。
<termEntry>は用語の項目レベルの要素であるが、TBXではさらに上位概念の体系、つまりISO 12200のMARTIF(Machine-readable terminology interchange format)を実装している。MARTIFからtermEntry以下までの構造を示すと図8のようになる。
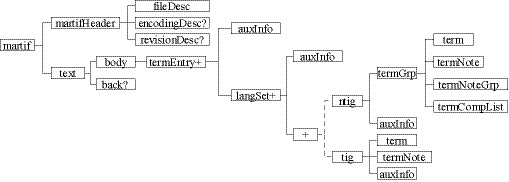
図8:MARTIFの構造
<martif>はTBXインスタンス文書のルート要素である。<martif>はヘッダ情報である<martifHeader>と、用語集の内容である<text>に分かれる。<text>はさらに用語の本体である<body>と後付け情報である<back>に分かれている。
<martif>から始まり、<term>に至るまでの体系は、実はISO 16642のTMFメタモデルに準拠している)。TMFとは用語マークアップフレームワーク(Terminological Markup Framework)のことである。TMFの概念構造を図9に示す。
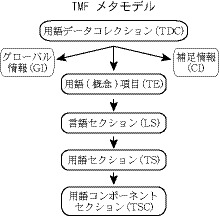
図9:TMFの概念構造(ISO30042の図1)
TDC(Terminological Data Collection)が<martif>レベル、GI(Global Information)が<martifHeader>とそれ以下、CI(Complementary Information)が<back>とそれ以下、TE(Terminological(Concept)Entry)という項目レベルが<termEntry>、LS(Language Section)の言語レベルが<langSet>、TS(Term Section)やTCS(Term Component Section)などの用語レベルが<tig>や<ntig>以下に対応している。
実はTBXのベースになったもう一つ重要なISO規格がある。それは汎用的に使われるデータカテゴリを定義したISO 12620である。たとえば、TBXの例にある次の要素に注目する。
<termNote type="partOfSpeech">noun</termNote>
これは品詞が「名詞(noun)」であると説明したが、その根拠となるのは<termNote>のtype属性である。このtype属性の属性値である「partOfSpeech」がデータカテゴリを示している。"part of speech" は文字どおり英語で「品詞」を表わしている。同様に、フランス語やドイツ語など、男性形、女性形、中性系などの変化がある言語の場合、それを識別するためのデータカテゴリは「grammaticalGender」である。こうした一般的なデータカテゴリをあらかじめ定義してあるのがISO 12620である。
そして特定のTMLつまり用語マークアップ言語でどのようなデータカテゴリを使用するかは、XCSで定義するのである。
TBXに関係するISOの関連規格の関係を図10に示す。
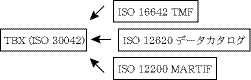
図10:TBXと関連するISO規格
このようにTBXを概観すると、用語集といえども、データの汎用的な交換を実現するには、さまざまな概念とフレームワークを駆使しなければならないことに気づかされる。
2.4 XML Text Memory(xml:tm)
XML Text Memoryつまりxml:tmは比較的新しい規格 であり、LISAの規格になったのは2007年2月である。xml:tmには、名前空間の機能を使って翻訳メモリを直接xml文書の中に記述するという特徴がある。Text Memoryという名称のとおり、「テキスト」の中にメモリがあるのが強みになっている。TMXの場合、原典ファイルとは別に翻訳メモリを管理することになるが、xml:tmでは原典と翻訳メモリを対で管理することになる。原典となるものを執筆メモリ(Author Memory)、翻訳後のメモリを翻訳メモリ(Translation Memory)という。
簡単な例を取り上げる。夏目漱石の有名な小説は次のように始まる。
<utj:p>
吾輩は猫である。名前はまだ無い。
</utj:p>
これをxml:tmで表現すると、図11のようになる。名前空間がtm:の要素がxml:tmである。執筆メモリは原典である。翻訳メモリは翻訳後の状態を示している。
|
執筆メモリ <utj:p> <tm:te id="e1" tu="2" version="1.0"> <tm:tu id="u1.1" crc="8511022a" version="1.0"> 吾輩は猫である。 </tm:tu> <tm:tu id="u1.2" crc="3131fa57" version="1.0"> 名前はまだ無い。 </tm:tu> </tm:te> </utj:p> |
⇒ |
対応する翻訳メモリ <utj:p> <tm:te id="e1" tu="2" version="1.0"> <tm:tu id="u1.1" crc="7643022a" version="1.0"> I am a cat. </tm:tu> <tm:tu id="u1.2" crc="31bd5477" version="1.0"> As yet I have no name. </tm:tu> </tm:te> </utj:p> |
この例の場合、utjとtmという二つの名前空間が混在しているので読みにくいが、<p>の段落は1つのテキスト要素(Text Element、<tm:te>)として認識され、それがさらに各文つまりセグメントに対応する2つのテキストユニット(Text Unit、<tm:tu>)に分かれている。テキストユニットが2つあることはtm:te要素のtu属性の値 に示されている。
tm:tu要素のcrc属性はCRC(Cyclic Redundancy Check) の16進のハッシュ値を示すもので、これはxml:tmのメモリが壊れていないことを確認するためのものである。ちなみに例示したcrc値は正確ではない。
xml:tmで重要な属性はidである。このidは、執筆メモリでも、翻訳メモリでも、文書の存在期間にわたって一意になるように管理される。これまで翻訳におけるメモリのマッチは原典に含まれる原文との照合だったが、xm:tmが原典テキスト上で各テキストユニットに固有のidをふり、そのidも含めて照合を行うことにより、文脈を踏まえた照合を行えるようになった。
xml:tmでの翻訳メモリのマッチの種類には、次のものがある。
イグザクト・マッチ(Exact Match)
文書内のレバレジド・マッチ(In-document Leveraged Match)
文書内のファジー・マッチ(In-document Fuzzy Match)
イグザクト・マッチつまり完全な一致は、xml:tmの場合、原文だけでなくid属性の値も含めて一致した場合の状況である。レバレッジド・マッチとは、そのテキストユニットに内容の変更はないものの、その直前のテキストユニットに変更や削除があったために訳文の確認が必要となる場合の状況である。ファジー・マッチは変更が加えられたが、変更前の訳文を参考にできるような状況を示す。
これまで翻訳メモリは文脈と切り離して管理されてきたが、xml:tmの場合はテキストメモリという特性とid属性を活用して、文脈を伴うメモリの管理を実現している。
▲このページのTOPへ







▲NeoCoreについて記載されています!
▲XMLマスター教則本です。試験対策はこれでばっちり!
