NeoCoreXMS徹底解剖 4
![]()

NeoCore XMS を普通に使うだけならば、どのような仕組みで動作しているかを知っておくことは、必須ではない。しかし、効率的な検索を行うためには基本的な動作原理を理解しておくことが望ましい。
NeoCore XMS の特徴は、USP(米国特許)取得技術であるDPP (Digital Pattern Processing)と呼ばれる、独自のインデックス検索技術をベースとしているところにある。DPP は、連想メモリーを用いたパターン認識技術のひとつで、それ自体は XML とは関係がない。DPP では、検索対象としてパターンが与えられると、対象となるパターンの集合の中から一致するものを高速に取り出すことができる。パターンを取り出すための所要時間はパターンの総数に関係なく、平均で1.5 メモリーサイクルとのことである。つまり、どれほど多くのパターンがあったとしてもほぼ同じ短い時間で取り出せることになる(図10)。DPP での探索の対象としてアイコンと呼ばれる64 ビットの固定長のパターンが用いられる。
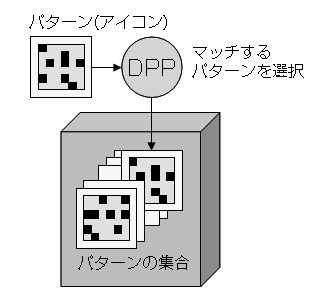
図 10:DPP によるパターンマッチング
NeoCore XMS では、このDPP 技術をインデックスメカニズムとして用いることによって高速検索を実現している。XMLドキュメントのタグ情報と内容情報がアイコンに変換され、インデックスとして利用される。XML ドキュメントの階層構造は、構造の末端にくる各データと、そのデータまでの絶対パスを合わせた文字列のリストとして各データを表現するパス形式に変換することができる。このうちのパスの文字列と、パス+データの文字列のそれぞれがDPP のアイコンに変換される。
XML ドキュメントがNeoCore XMS に登録されると、自動的にこれらのインデックスが生成される(図11)。インデックスの作成は完全に自動であるため、ユーザはどの項目にインデックスを設定すればよいかは考える必要はなく、インデックスが使用されるような検索を考えるだけで済む。
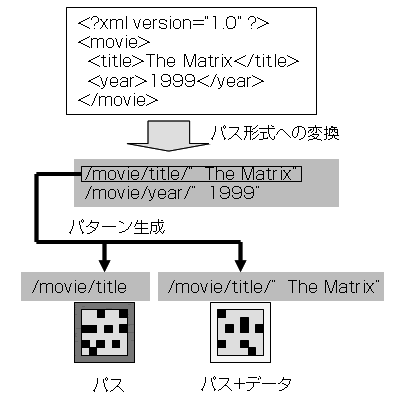
図 11:XML ドキュメントからのインデックス作成
検索時には、検索式からも同じようにしてアイコンを生成し、インデックスのアイコンをDPP を用いて検索することで、インデックスを高速検索する。XML ドキュメントの検索は、必ずしもインデックスが一致するような検索ばかりではないので、その場合には、通常の検索技術が併用される。したがって、NeoCore XMS を効果的に利用するためには、インデックスが有効に働くように、パスやデータが完全一致するような検索式を多用することがポイントとなる。
NeoCore XMS は、登録されたXML ドキュメントを、インデックスを中心とする複数のファイルに分解して格納する(図12)。生成される主なファイルはマップファイル、辞書ファイル、コア・インデックス、重複ファイルの4 種類である。
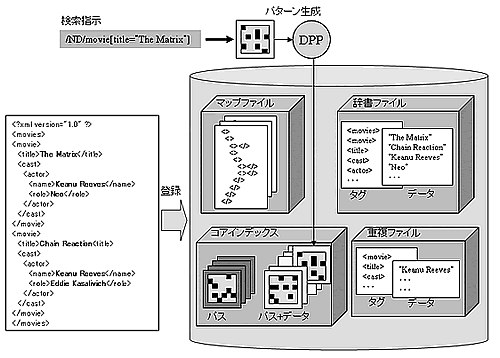
図 12:データベースの構成
■ マップファイル
XML ドキュメントはタグの情報とデータ(内容の文字列)で表現された階層構造である。このうち、タグとデータについての具体的な情報を除き、位置関係によって階層構造だけを記述したものがマップファイルである。
■ 辞書ファイル
XML ドキュメントに含まれるタグの具体的な情報を管理するタグ辞書と、データの具体的な情報を管理するデータ辞書からなる。マップファイルから、タグ辞書およびデータ辞書を参照することによって、XML ドキュメントを復元することができる。
■ コア・インデックス
インデックスは、XML ドキュメントの階層構造の探索を上位の階層から順に行うのではなく、値から逆引きを行うためのメカニズムである。タグの値によるインデックスと、タグとデータを合わせた値によるインデックスがそれぞれ用意される。NeoCore XMS では、インデックスはすべてのタグについて定義される。
■ 重複ファイル
インデックスファイルの中で、繰り返して登場したものは、重複ファイルによって管理される。
それぞれのファイルは、データベース作成時に与える設定パラメータの値に従って生成される。XML ドキュメントが登録されると、ファイル中の領域が消費されるが、ファイル自体のサイズが増加することはない。
▲このページのTOPへ






