隠されたニーズを引き出すXMLデータベース 「第2回 その要求と分類」
著者:ピーデー 川俣 晶
前回は、RDBでは上手く扱うことができないニーズが存在することについて説明した。つまり、これから開拓すべきニーズがまだ多数眠っているということである。そして前回の最後には、XMLデータベースがそれを解決する技術であると紹介した。
そこで、今回は「XMLデータベースとは何か」をXMLデータベースの分類も踏まえて説明していく。
そして次回に、RDBが満たせなかったニーズをXMLデータベースがいかにして満たすかについて説明していく。
XMLデータベースとは何か
XMLデータベースを一言でいえば、XML形式のデータを記録・検索するためのデータベースである。
しかし、「なぜXMLデータベースが必要とされるのか」や「XMLを使うこととXMLデータベースを使うことはどのように違うか」を理解するには、まずXMLについて知らねばならない。
そこで、軽くXMLについてのおさらいをする。
XMLとは
XMLとは、Extensible Markup Languageの略であり、WWWの標準を定める団体であるWorld Wide Web Consortium(W3C)より1998年に勧告(Recommendation)されたメタ言語である。
メタ言語とは、言語を作るための言語である。このように説明すると非常にわかりにくいという印象を持つ読者も多いが、それは間違いではない。
ここでは、XMLは言語を作る手段だと理解すればよいだろう。そこで作られる言語には、広い世界で使われるものもあれば、特定の組織内限定といった狭い世界で使われるものもある。
広い世界で使われる例は、インターネットのコンテンツを記述する言語であるXHTMLなどがある。一方狭い世界の例は、特定の会社の人事情報を記録するための専用言語というようなものである。
これらの言語は、何かの情報を電子形式で保存するために使用される。ここでは、以上のように理解しておけばよい。XMLを理解することは難しいが、この記事を読むにはこの程度の理解で十分である。
XMLは難しいという認識は必ずしも社会的に共有されたものではない。XML普及の初期の段階では、普及を最優先とするために、XMLは簡単でわかりやすいという主張が多く行われたが、これは必ずしも適切ではなかった。
なぜなら、XMLをわかっていないにも関わらず、XMLをわかったと思いこんだ多くの人たちを生み出し、彼らがXMLビジネスを主導するような形になってしまったからである。
当然、正しい理解を欠いた者たちが主導するビジネスが上手くいく訳がない。XMLビジネスの大半は、まさに死屍累々という惨状である。XMLの専門雑誌を刊行する動きはいくつかあったが、いずれも数回の発行で終了している。
またXMLを用いたビジネスの目玉とされていたのは企業間の電子商取引である。しかし紙の見積書や請求書がすべてXMLにより標準化された電子文書で交換される時代は到来する気配もない。
それとは別にXMLを用いた技術の本命とされたWebサービス(SOAPというプロトコルを用いた分散処理)も盛り上がりを見せない。例えば、SOAPとライバル技術の両方を公開して提供したサービス業者の場合、SOAPよりもライバル技術の利用者の方が多いという結果を残している。
つまり、これがXMLビジネスの惨状である。
幅広く普及するXML
XMLビジネスのこの惨状を知れば、XMLに関わることに意味がないと感じるかもしれない。まして、XMLデータベースなどというものに取り組むのは無意味と感じられるだろう。
だが、実はXMLビジネスがこれほどの惨状を示しているにも関わらず、XMLは幅広く普及が進んでいて、各方面で活発に利用されているのである。
「そんな馬鹿な」と思う方は、もしテキストエディタのファイルの検索機能を利用できるのであれば、ご自身のパソコンの中で"<?xml ......"ではじまるテキストファイルを探してみるとよいだろう。
大抵のパソコンでは少なくとも数個以上の該当ファイルが発見できると思うが、これがXMLによって記述された情報である。今や、XMLを使っているなどということは、宣伝文句にもならない。様々なシステムが、XMLを利用して構築されているのである。
つまりXMLビジネスは惨状なのに、XMLを利用したシステムは幅広く存在するのである。一見して矛盾しているように思われるこの状況は、どうして発生したのだろうか。
その理由はいくつか考えられるが、その1つを説明しよう。
XMLは「言語を作る」手段という機能性を持つ。つまり、XMLは既存の技術では上手く扱えない情報を保存するために、専用の言語を作り使用することができる。このような情報の多くは、特定の組織内や特定のソフトからのみ利用されることになる。
そのようにして使われるXMLは、大々的に宣伝されるものではないし、利用目的も千差万別であり何かの流行になることもない。また、企業間の電子商取引やWebサービスのように、お仕着せ(注1)の機能とも馴染まない。お仕着せの機能では済まされないニーズに対応して使われるのがXMLなのである。
※注1:お仕着せ(型どおりのもの)
このような状況を背景に、実はXMLの普及は著しいものがある。組織内の独自書式の情報などは、標準技術には上手く収まらないことが多い。それを上手くすくいあげてくれるのがXMLだったわけである。
その意味で、XMLは大成功をおさめたといってよいだろう。
XMLに対する次なる要求
例えば、過去のしがらみから特殊な書式の書類を多数使っている企業のことを考えてみよう。
書類の電子化という要求がでてきたとき、まず考えられるのはワープロや表計算ソフトを使うことだろう。
しかし、それは十分な解決手段にはならない。なぜなら書類の自動処理ができないからだ。
例えば表計算ソフトで請求書を作成することは簡単にできる。しかし、どのセルにどのような数字を記入するかは決まっていないので、数字を自動チェックするシステムを作ろうとしても上手く作成できないのである。
これを解決する方法はいくつかある。そのうちの1つが、特殊な書式の情報を記述する言語をXMLで作り、その情報を入力してXML文書ファイルを作成する入力フォームを用意することである。
この方法は、すべてを独自に開発するケースと比較して、多くのXML関係の既存ツールを使用することができるため、遙かに短い時間と低いコストで実現できる。つまり、たいへん有益で役に立つ選択の1つといえる。
ところが、これは便利だと思って本格的に組織をあげて使いはじめると、すぐに大きな問題に遭遇することになる。
XML文書ファイルは、一種のテキストファイルとして保存されるため処理の効率が低いのである。
例えば、100MBのXML文書ファイルが存在するとき、そのファイルの最後の方に記録された情報を取り出すには、通常100MBのファイルを最初から順に調べていかねばならない。これは、すぐに結果を知りたいときには非現実的な時間を要する処理といえる。
また、ファイルの数が増えても同じような問題が発生する。XML文書ファイルの数が数千、数万と増えていったとき、特定の情報を検索するにはそれらのファイルをすべて調べる必要がある。これは、ただでさえテキストファイルであるため処理の効率が悪いXMLにとっては致命的な弱点となる。
つまり、データ量の増加に弱いのがXMLの弱点であり、データ量が増えた場合でもXMLを活用したいという要求が発生したわけである。
その要求に対応する技術の1つがXMLデータベースである。
XMLデータベースは、XMLデータをテキストファイルではなく、専用のデータベースに格納することにより、データ量が増えても高速な処理を実現するのである。
XMLデータベースの分類
「XMLデータベースさえ使えばXMLの弱点をカバーすることができ、我が社に飛び交う特殊な書式の文書も上手く電子化できるのか」と思うのはまだ待っていただきたい。
実は、XMLデータベースと呼ばれるソフトウェアは多数存在するが、それらに共通するのは「データ量が増えてもXMLデータを高速に処理できる」ということだけなのである。それを実現する方法も1つではなく、実現方法によって受ける制約も1つではない。加えて、どの程度の量までデータを扱うことができるか、その水準もまた様々である。
つまり、ただ単にXMLデータベースを導入すれば必ず上手くいくものではない。千差万別のXMLデータベースの個々の特徴を理解し、ニーズにあったソフトウェアを導入する必要があるのだ。
それでは、XMLデータベースの分類についていくつか紹介しよう。
世代による分類
公式の分類ではないが、便宜上、第1世代、第2世代という分け方がある。
実は、1998年にW3CがXMLを勧告してからさほど時間を置かずにXMLデータベースが誕生している。
この時代、まだXMLとはエキサイティングな最新技術であり、XMLという3文字さえ冠しておけば注目を集められた。そのような時代に生まれてきたXMLデータベースとは、XML形式のデータを格納するためのデータベースという位置づけであり、単に格納できるというだけで存在意義を認められていた。これが便宜上第1世代と呼ばれるXMLデータベースである。
例えば、Xcelon(Sonic XIS)、Xindice、Yggdrasill、Taminoなどが第1世代のXMLデータベースとされる。
それに対して、2005年から徐々に日本でもはじまるXMLデータベースのブームで注目されているソフトウェアが、便宜上第2世代のXMLデータベースと呼ばれている。これらのソフトウェアは、XMLブームの熱狂が去った後に生まれてきたものであり、単にXMLデータを格納できるというだけでは許されず、それが本当に役立つかを判断する厳しいチェックを抜けてきたものである。つまり、信頼性や性能などにも高いハードルが要求されているということである。
例えば、NeoCoreXMS、TX1、Shunsakuなどが第2世代のXMLデータベースと呼ばれている。

▲図1:世代による分類
XMLデータベースの第1世代と第2世代の差は、それが生まれた目的の相違として捉えるとわかりやすいかもしれない。つまり、第1世代はXMLデータを格納することが目的であったが、第2世代は大量のデータを柔軟に扱うために、XMLという技術を取り込んだデータベースだということである。そして第1世代に主役であったXMLは、第2世代の頃には脇役に引っ込んでいて、代わりに主役にでてきたのは「大量のデータを柔軟に扱いたい」というユーザニーズである。
ゆえに、第1世代は技術主導で、第2世代はニーズ主導という分類もできるが、実は技術的に見ても第2世代の方が遙かに高度である。それだけの技術力を用いなければ、ユーザニーズは満たせないということである。
では、それほど困難なユーザニーズとは何か。
信頼性や可用性などの要求もあるものの、最大の要求は「ずば抜けて大きなデータを素早く扱う能力」である。
実はデータ量に対するXMLデータベースへの要求は大変にレベルが高い。例えば、RDBで扱うのと同程度の量のデータを、遜色ない速度で処理することが要求されるのはよくあることである。さらにナレッジマネジメントのような用途が想定される場合、既存のRDBなどのデータベースを集めた大データベースを作成する関係上、RDBよりも多くのデータを素早く処理する能力が要求されることもある。
スキーマによる分類
XMLでは、スキーマというデータを定義する文書が使われる。スキーマはDTD、W3C XML Schema、Relax NGなどのスキーマ言語で記述され、XMLデータがあらかじめ決められたルールに従っているかを検査するために使用できる。
例えば、「名前」要素(要素はXMLで情報を記録する単位)には、「姓」要素と「名」要素が必須であるとスキーマで規定した場合、「姓」要素はあるのに「名」要素が欠けている文書は誤りであると報告することができる。
とはいえ、XMLにおいてスキーマは必須ではなく、スキーマのないデータを扱うこともできる。これがXMLの持つ一種の柔軟性である。
さてスキーマは文書のチェックだけでなく、XMLデータベースの構造を定義したり、処理速度を向上するために使用することができる。
実際にXMLデータベースは、スキーマへの対応で以下の3種類に分類することができる。
| スキーマは必須 | データベースを作成する際、スキーマを指定する必要がある。また、スキーマに合致しないXMLデータは格納することができない。つまりXMLではスキーマのないデータも認められているが、これを格納することはできないという制約を持つ。 |
|---|---|
| スキーマがあれば性能が向上する | スキーマを指定せずにデータベースを作成することができる。しかし、スキーマを指定することで、データベースの検索などの性能を向上させることができる。 |
| スキーマ不要(スキーマレス) | スキーマを指定することは一切不要。スキーマを指定せずとも高性能を発揮できる。最も制約が少なく、あらゆるXMLデータを差別なく扱える。 |
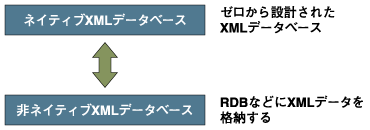
ネイティブであるか否かによる分類
XMLデータベースは、最初からXMLデータを扱う専用ソフトとして設計される場合と、既存のRDBなどにXMLデータを格納することによって擬似的にXMLデータベースとして振る舞うように設計する場合がある。
前者はネイティブXMLデータベース、後者は非ネイティブXMLデータベースと呼ばれる。
▲図2:ネイティブか否かの分類
ネイティブXMLデータベースと非ネイティブXMLデータベースを比較した場合、それぞれに長所と短所が存在する。
非ネイティブXMLデータベースは、データを記録する部分に実績のあるRDBなどを使用するため、データの安全性、可用性などについては既存のRDBと同水準のものを得ることができる。反面、まったく異なる構造を持ったデータベースにデータを格納するため、格納できるデータに対する制約は多くなる(例えばスキーマに対する制約がつくなどの事例がある)。
一方、ネイティブXMLデータベースは非ネイティブXMLデータベースのような制約は少なくて済むものの、長年使われてきたRDB製品と比較すると、安全性や可用性の面で見劣りする部分や実績不足の面があることは否めない。
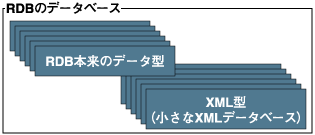
ハイブリッド型データベース
これまで説明してきた分類とは別に、RDBがXMLデータベースの機能を取り込んでしまい、どちらとも言い難い構成になっているものが存在する。
▲図3:ハイブリッド型データベース
例えば、Microsoft SQL Server 2005は、RDBのデータ型としてXML型というものをサポートしている。これを使うとRDBのデータベースの中に、小さなXMLデータベースを多数含めることができる。
このようなデータベースは、既存のRDBによるデータベースに、変化を受け入れる柔軟性を追加するには便利である。RDBとして設計されたデータベースはそのまま継続して使用しつつ、そこに柔軟に変化しうる項目を付け足すことができるからである。
しかし、ただ単に巨大なXMLデータや大量のXMLデータを扱いたいというニーズにはあまり便利ではない。大量のデータの高速検索はRDBの機能を使って行うことが前提となっているため、XMLデータの検索は十分な性能がでないこともあり得るだろう。
クエリ(問い合わせ)言語
データベースを活用する際には、クエリ(問い合わせ)言語が不可欠である。
RDBでは、SQL(Structured Query Language)が標準的に使用されるが、XMLデータベースでは、XQueryというクエリ言語が標準とされることが多い。
XQueryは、SQL技術者が習得しやすいように配慮された言語である。とりあえず書けるようになるだけなら僅かな講習だけで可能との意見もあり、普及が期待される。
しかし、XQueryはまだ完全ではない。
XQueryは、XMLと同様にW3Cで制定が進められているが、まだ勧告される段階に至っていない(注2)。
※注2:現在(2006年2月9日)は勧告候補の段階(Candidate Recommendation)である。
そのため、各XMLデータベース製品は、作業中の仕様書を元にXQueryの実装を行っているが、使用する仕様書の版によって仕様が異なることがあり、一定していない。また、すべての機能を実装していないケースやそもそもXQueryを採用していないケースもあり、一筋縄ではいかない。

▲図4:クエリによる分類
XQueryの相違はやむを得ないと考え、XQueryを採用したXMLデータベースと、採用していないXMLデータベースに分類することは有益だろう。
ちなみに、XQueryをサポートするXMLデータベースはNeoCoreXMSなどであり、サポートしていないのはShunsakuなどである。
ではどれを使えばよいのか
これまで説明してきた通り、XMLデータベースには様々な分類があるが、それぞれには強い制約が付く場合があり、どれを使ってもすべてのニーズを満たせるとはいえない。
では、いったいどれを使えばよいのだろうか?
前回説明した眠っている潜在的なニーズを満たすためには、どのような特徴を持ったXMLデータベースを選択すればよいのか。そして、それをどのように使っていけばよいのか。
その答えを次回に明らかにしていく。
▲このページのTOPへ






