RDBとXML DB規格「1.これなら簡単 RDBからXML DBへのデータ移行」
- 1
- 2
なぜRDBを捨てられないのか
アプリケーションデータの構造が複雑化するにつれ、リレーショナルデータベース(以下、RDB)のテーブル設計が困難となるケースが増えている。例えば、企業の組織/社員データなどが典型だ。幾重もの階層構造を伴うこれらのデータは、単一のテーブルでは表現できないから、いくつものテーブルに分割せざるを得ない。しかも、階層が複雑になれば、分割したテーブル同士を仲介するためのマッピングテーブルも用意しなければならず、直感的なテーブル設計を困難なものにしてしまう。データを参照する際にも、複数のテーブルをJOIN(結合)する操作が必要になるから、処理パフォーマンス低下の原因となる。
また、システムの開発リードタイムが短くなっていることも開発者を悩ませている原因だ。開発リードタイムの短期化は、あいまいな設計に直結する。ユーザー要件が明確にならないままに、開発・コーディングを進めなければならないという状況だ。そのようなケースでは、往々にしてデータスキーマの一部が下流工程で変更になる。しかし、厳密なスキーマ(構成)情報を必要とするRDBでは、開発工程の後半になればなるほど、変更のインパクトは大きくなるのが常だ。あいまいな設計のままに進めた開発は、下流の作業に多くの無理を強いることになる。また、変更要求は開発中ばかりではない。システムリリース後も、日々のビジネス変動によって、データスキーマは常に変更の可能性にさらされている。
一方、XML DBならば、必ずしも構造が明確でない半構造のXMLデータをそのまま格納できる。スキーマにとらわれないから、アプリケーション開発途中やカットオーバー後の構造変更にも比較的容易に対応できる。ところがXML DBの優位性を分かっていながら、それでもRDBに執着してしまう開発者はいまだに多いという。
XML DBでの開発にはなかなか踏み切れないのはなぜだろうか。これには、XMLのツリー構造でデータを定義した経験がなく、なんとなく覚えるのが大変そうだといった、いわゆる「食わず嫌い」が大きく影響しているようだ。ツリー構造の設計は決して難しいものではない。むしろすべてのデータを2次元表に押し込めてしまうRDBの世界に比べれば、圧倒的に「直感的な」構造である。そこで本記事では、いったんRDBのテーブル構造に格納してしまった既存データを、XMLのツリー構造で再定義するまでの過程を解説することで、RDBの感覚にどっぷり浸ってしまった開発者のXMLアレルギーを解消してみよう。
RDBモデルとXMLモデルの違いを知る
RDBモデルにおける2次元表とXMLモデルにおけるツリーデータとの決定的な相違点とは「データ表現の自由度」にある。以下の図をご覧いただきたい。
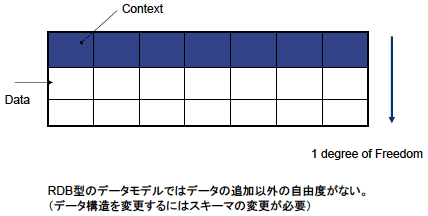
図1 RDBモデルのデータ表現
Context(フィールド定義)はあらかじめ規定されているとするのがRDBのデータモデルだ。自由度として与えられているのは、データを1行ずつ追加する1次元の操作のみである

図2 XMLモデルにおけるツリーデータ
Context(データの定義)、Data(データそのもの)、Structure(データ構造)の3次元の自由度を持つXMLのデータ構造
RDBモデルでは、あらかじめ厳密なフィールド定義(Contextの決定)が前提となる。つまり、決められたフィールドに合致したデータ(レコード)を追加する自由度しかない。これに対しXMLモデルのツリー構造は、半構造データが特徴だ。半構造データとは、構造自体は持っているものの、RDBモデルのようにあらかじめ定めたレイアウトに拘束されない可変的なデータのことをいう。つまりデータ表現の変更では、データそのもの(Data)の変更はもちろん、データの定義(Context)、データ構造(Structure)にわたる変更を柔軟に行えるのだ。
別稿「徹底比較 RDB vs XML DB」でも紹介したように、例えば注文データにおいて新たに仲介業者情報を追加したいと思ったら、XMLツリーでは部分木をただ「接ぎ木」すればよいのだ。これがRDBモデルの場合、新たなテーブルを別に設計したうえで、さらに既存のテーブルには新たなテーブルと結合するための新規カラムを追加しなければならない。
それならば、RDBからデータ構造の変更に強いXML DBにデータを移行すればよいわけだが、ここで失敗するケースは少なくない。RDBモデルで表現された2次元表データを単純にXMLモデルのツリー構造に移行すれば済むのかというと、そうではないのだ。テーブル型思考とツリー型思考とでは、基本的な設計ポリシーが異なる。その違いを理解していなければ、せっかくXML DBに移行しても、思わぬ落とし穴に陥ることになってしまう。
RDBモデルをXMLモデルにそのまま移行した例
テーブル型思考に慣れたエンジニアが犯しやすい失敗を、具体的なサンプルを示して検証してみよう。以下のような顧客データがRDB上にあったと仮定する(以下の図は、Accessのリレーションシップでスキーマ関係を表現したもの)。
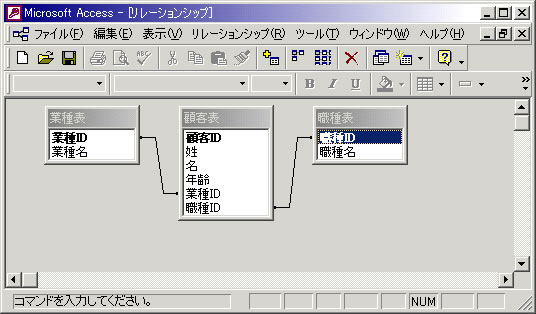
図3 顧客データのサンプル
RDBで3つの表に正規化された顧客データ。データの冗長化を避けるため、繰り返し入力される「業種名」と「職種名」を別テーブルに分離し、主キーによって顧客表に関連付けている
これをXMLモデルに置き換えてみると、どのようになるだろう。以下は、テーブル型思考をそのままに、RDBモデルをXMLモデルに置き換えてみた例だ。
コード1 RDB型思考で作成したXMLデータ(customer01.xml)
<?xml version="1.0" encoding="Shift_JIS" ?>
<データ>
<顧客データ>
<顧客>
<顧客ID>1</顧客ID>
<姓>小野</姓>
<名>伸二</名>
<年齢>23</年齢>
<業種ID>2</業種ID>
<職種ID>3</職種ID>
</顧客>
<顧客>
<顧客ID>2</顧客ID>
<姓>中村</姓>
<名>俊輔</名>
<年齢>24</年齢>
<業種ID>1</業種ID>
<職種ID>1</職種ID>
</顧客>
</顧客データ>
<業種データ>
<業種>
<業種ID>1</業種ID>
<業種名>情報通信</業種名>
</業種>
<業種>
<業種ID>2</業種ID>
<業種名>小売</業種名>
</業種>
<業種>
<業種ID>3</業種ID>
<業種名>流通</業種名>
</業種>
</業種データ>
<職種データ>
<職種>
<職種ID>1</職種ID>
<職種名>SE/プログラマ</職種名>
</職種>
<職種>
<職種ID>2</職種ID>
<職種名>ITコンサルタント</職種名>
</職種>
<職種>
<職種ID>3</職種ID>
<職種名>プロジェクトマネージャ</職種名>
</職種>
</職種データ>
</データ>
XMLの構文という意味では、なんら間違いはない。Well-Formedな(整形式)XMLだ。しかし、XMLモデルに適したデータ構造かというと、多く課題が残る。
まず1つに、アプリケーションからの直接的なアクセスが難しい点が挙げられる。このXMLデータから顧客IDをキーにして、顧客の職種名を取得したいとしたらどうだろう。XPath(注)より以下のような2段階の問い合わせを行わなければならない。
XPath式による問い合わせ 1
顧客データ/顧客[顧客ID="1"]/職種ID ・・・・・・・・・・・・・・・・・・・・・・・・・・・・・①
職種データ/職種[職種ID="(1)の結果"]/職種名< ・・・・・・・・・・・・・・・・・・②
注:XPath(XML Path Language)
XPathは、XML文書の特定の部分を指し示す構文を規定する。XPathを利用すれば、XML文書中にアンカーなどが埋め込まれていなくとも、文書中の任意の位置を指し示すことができる。
これでは、RDBモデルをXMLモデルで再構築した意味がまったくない。なぜならRDBで行っていたJOINの数だけ、XMLモデルではXPathによる問い合わせを行わなければならないからだ。当然、データ構造の複雑度に比例して、アプリケーションコードは複雑になる。
また、スキーマ変更に対する耐性にも問題がある。この顧客データに新たに「地区データ」を追加したいと思ったらどうだろう。上記と同じ要領で要素を追加するならば、以下のように<地区データ>要素を追加すると同時に、<顧客>要素の配下にも<地区データ>要素と関連付けるための<地区ID>要素を追加しなければならない。つまり、単純にその情報を必要とするノード配下に部分木を「接ぎ木」するという操作では済まなくなってしまうのだ。ましてや、追加対象のデータが複数の顧客データにまたがっていたり、あるいは、追加する情報そのものが多くなってくれば、結局、スキーマ変更は煩雑となってしまい、XMLモデルの柔軟性を生かすことができなくなってしまう。
コード2 RDB的なXMLのスキーマ変更のインパクト(customer02.xml)
<?xml version="1.0" encoding="Shift_JIS" ?>
<データ>
<顧客データ>
<顧客>
<顧客ID>1</顧客ID>
<姓>小野</姓>
<名>伸二</名>
<年齢>23</年齢>
<業種ID>2</業種ID>
<職種ID>3</職種ID>
<地区ID>1</地区ID>
</顧客>
......中略......
</顧客データ>
......中略......
<地区データ>
<地区>
<地区ID>1</地区ID>
<地区名>商業地区</地区名>
</地区>
......中略......
</地区データ>
</データ>
正規化されたテーブルをフラットなデータに
上記の例でも分かるように、RDBモデルのデータをそのままXMLモデルに移行するだけでは、XMLモデルの利点は生かせないのだ。
それでは、RDBからXMLへの移行に当たってどのような手順を踏めばよいのだろうか。XMLというと、とかくツリー階層であるという点が強調されるせいか、無理に階層構造を作ろうと考えがちであるが、なにも最初から階層構造を強く意識する必要はない。特にXML DBに格納するXMLデータであればインデックスを使用して検索を行うので、階層を持たないフラットなデータでも問題はないのだ。というよりも、無意味な階層を付けることは、アプリケーションからの問い合わせを煩雑にするだけで、これといったメリットはない。それならば、まずは正規化されたRDBのテーブルをJOIN句で結合し、最も単純なフラットの顧客データを作成してみよう。3つの表を結合した結果は、図4のとおりだ。
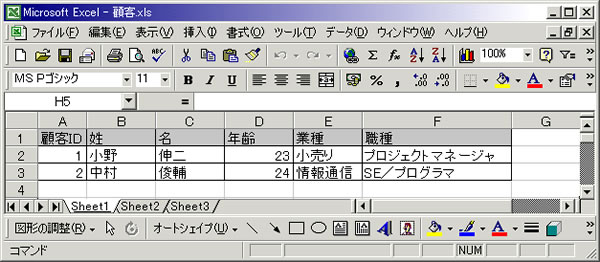
図4 RDBの顧客表から作成したフラットな顧客データ
3つの表に正規化されていたRDB上の顧客データ(図3)から、JOIN句を使ってデータを抽出したイメージ。
これをXMLモデルで表現してみると、以下のようになる。
コード3 フラットなExcel形式のデータからXMLを作る(customer03.xml)
<?xml version="1.0" encoding="Shift_JIS" ?>
<顧客データ>
<顧客>
<顧客ID>1</顧客ID>
<姓>小野</姓>
<名>伸二</名>
<年齢>23</年齢>
<業種>小売</業種>
<職種>プロジェクトマネージャ</職種>
</顧客>
<顧客>
<顧客ID>2</顧客ID>
<姓>中村</姓>
<名>俊輔</名>
<年齢>24</年齢>
<業種>情報通信</業種>
<職種>SE/プログラマ</職種>
</顧客>
</顧客データ>
コード 1では冗長だったXMLデータが極めてシンプルになったことが分かる。これならば、特定の顧客IDをキーに業種を取得したいと思った場合にも、直感的なXPathで問い合わせを行うことができる。
XPath式による問い合わせ 2
顧客データ/顧客[顧客ID="1"]/業種
もしも新たに「地区データ」を追加したいと思った場合にも、<顧客>要素の配下に<地区名>要素を接ぎ木すればよいだけなので、スキーマ変更に対する耐性も生まれる。NeoCore XMS(Xpriori)のようにフルインデックスのXML DBを用いている場合には、すべてのノードにインデックスが生成されるので、上記のようにフラットなXMLであってもパフォーマンス上は問題ない。
フラットなXMLに階層を追加する
ただし、コード 3ようなフラットなデータでは、扱う要素数が多くなってきた場合に、可読性が損なわれるという難点もある。該当の要素がどのようなカテゴリに属する情報なのかが分かりにくくなるためだ。また、ノード名の衝突を考慮する必要もある。そこで、後々のスキーマ変更に強いツリー構造を作るために、コード 4のように意味あるカテゴリの単位で少しずつ階層化を進めてみよう(「業種」と「職種」の親ノードを「回答」としたのは、アンケート回収アプリケーションを想定しているため)。
コード4 フラットなXMLに階層を追加する(customer04.xml)
<?xml version="1.0" encoding="Shift_JIS" ?>
<顧客データ>
<顧客 ID="1">
<名前>
<姓>小野</姓>
<名>伸二</名>
</名前>
<年齢>23</年齢>
<回答>
<業種>小売</業種>
<職種>プロジェクトマネージャ</職種>
</回答>
</顧客>
<顧客 ID="2">
<名前>
<姓>中村</姓>
<名>俊輔</名>
</名前>
<年齢>24</年齢>
<回答>
<業種>情報通信</業種>
<職種>SE/プログラマ</職種>
</回答>
</顧客>
</顧客データ>
いかがだろうか? これでずいぶんとXMLらしいXMLになった。
繰り返しではあるが、RDBとXMLとはまったく構造の異なるデータモデルだ。RDBのテーブル的思考をそのままにXMLデータを移行してもXMLの利点を生かせない。かといって、一気にXMLのツリー構造を定義しようとしても、慣れないうちはなかなかうまくいかないだろう。そこで、一度、正規化されたRDBデータをExcelワークシートで表現できるようなフラットなデータに変換してみよう。そこから徐々に階層構造を付けていくことで、ごく自然にXML的なデータモデルを作成できるはずだ。難しく考えず、まずは手元のRDBデータを本記事の手順に従ってXMLデータに移行してみよう。
- 1
- 2
▲このページのTOPへ






