RDBとXML DB規格「2.徹底比較! RDB vs XML DB」
- 1
- 2
今なぜ、XMLデータベースなのか?
「XMLデータベース(以降、XML DB)」とは、XML文書をそのままの形式(ツリー構造)で格納可能なデータベースのことである。データベースというと、もっぱらOracleやSQL Server、DB2に代表されるようなリレーショナルデータベース(以降、RDB)が大勢を占める中、なぜ今、XMLデータベースに注目が集まっているのだろうか。
その最大の理由として、多くのシステム――特に分析・情報系のシステムにおいて、スキーマの変更が頻繁に発生する事例が増えているという点が挙げられる。現在のビジネス環境は極めて流動的だ。ビジネスが変われば、当然、管理すべきデータも変わるし、データを支えるアプリケーションにも影響が及ぶ。
従来のRDBは、厳密なスキーマ情報を前提とするデータベースモデルだ。つまり、管理すべきデータに変更があった場合には、常にスキーマ情報から変更しなければならないし、適正なパフォーマンスを望むにはインデックスも再構築する必要がある。ビジネスサイドからの要求によって発生するスキーマの変更、そして、それに伴うアプリケーション改定に翻弄されている保守担当者は、決して少なくないのではないだろうか。
このRDBが抱える問題を解決するべく登場したのがXML DBだ。XMLというデータ形式は、そもそも厳密なスキーマ構造を要求するものではない。そして、そのXMLデータを格納できるXML DBもまた、必ずしも構造が定まっていない半構造のデータを「そのまま」格納できるデータベースなのだ。構造にとらわれないから、日常的な構造変動にも比較的容易に対応できる。以下に、具体的なサンプルを挙げてRDBとXML DBの違いを検証してみよう。
スキーマ変更時のインパクトを検証する
企業間取引の一例として、以下のような構成の注文データがあったとしよう。取引先企業から物品を購入する際に使われる、ごく一般的なデータ構造である。
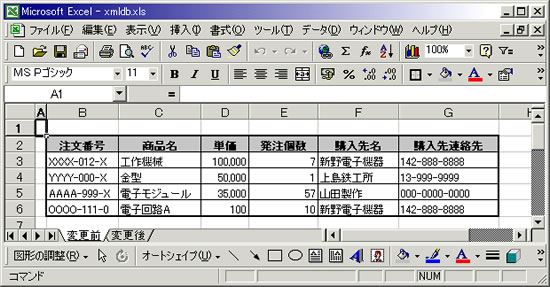
図1 注文データ(変更前)
注文番号、商品名、単価、発注個数、購入先名、購入先連絡先の6項目からなる一般的なデータ構造。
この注文データに対して、新たな取引形態が発生し、仲介業者情報が必要になったとしよう。つまり、ある商品を直接、生産メーカーから納品するのではなく、商社や仲介業者を介して購入するようなケースだ。ビジネスのグローバル化が進み、海外から安い製品を調達するといった場面が想定できるだろう。仲介業者情報を追加した注文データを以下に示す。
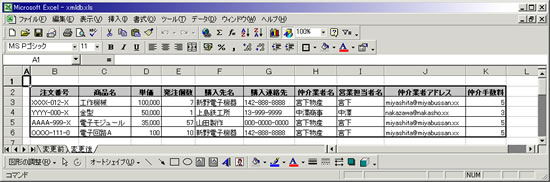
図2 注文データ(変更後)
変更前のデータ構造に、仲介業者名、営業担当者名、仲介業者アドレス、仲介手数料の4項目が追加された。
このようなスキーマの変更を、それぞれRDBとXML DBとで表現してみると、どのようになるだろうか。実はこの点が、XML DBとは何か、XML DBを導入するメリットはどこにあるのか、という本質的な問題を理解する重要な要素なのである。
RDBの場合
まずRDBの場合には、スキーマ変更の前後で以下のようなイメージになる(以下の図は、Accessのリレーションシップで変更前後のスキーマ関係を表現したもの)。
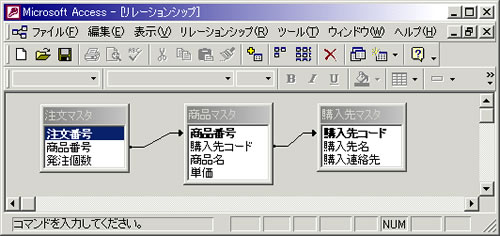
図3 RDBによる注文データ(変更前)
[注文マスタ]、[商品マスタ]、[購入先マスタ]の3つのテーブルに正規化。
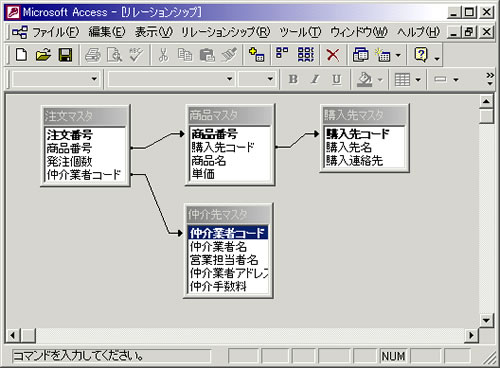
図4 RDBによる注文データ(変更後)
新たに[仲介先マスタ]テーブルを追加してスキーマ変更に対応した。
つまり、新たなテーブルとして仲介先マスタを追加し、かつ、プライマリテーブルである注文マスタに対して外部キー(仲介業者コード)を追加する必要があるのだ。もしくは、仲介情報そのものを注文マスタに追加しても構わないが、この場合は、仲介情報を必要としないすべてのレコードに対して、無駄なカラム領域の追加を強制することになる。
それだけではない。再構成されたデータベースに対して、最適なパフォーマンスを期待するためには、新たに追加された仲介情報に対してインデックスキーを追加する必要があるし、そもそもカラムの追加によってデータへのアクセスパス自体が変更になる場合には、データベース全体のインデックスを再検討する必要が出てくる。当然、これらの変更に伴って、アプリケーション側でも、仲介業者情報を参照するためのJOIN句を追加しなければならない。RDBにおけるスキーマの変更は、このようにデータベース、アプリケーション双方にさまざまな影響を及ぼすものなのである。
XML DBの場合
一方、XML DBの場合にはどうだろうか。以下の変更前、変更後のXMLコードを参照していただきたい。
コード1 XMLによる注文データ(変更前)
<注文データ>
<注文>
<注文番号>AAAA-999-X</注文番号>
<発注個数>57</発注個数>
<商品情報>
<商品名>電子モジュール</商品名>
<単価>35000</単価>
</商品情報>
<購入先情報>
<購入先名>山田制作</購入先名>
<購入先連絡先>000-0000-0000</購入先連絡先>
</購入先情報>
</注文>
......中略......
</注文データ>
コード2 XMLによる注文データ(変更後)
<注文データ>
<注文>
<注文番号>AAAA-999-X</注文番号>
<発注個数>57</発注個数>
<商品情報>
<商品名>電子モジュール</商品名>
<単価>35000</単価>
</商品情報>
<購入先情報>
<購入先名>山田制作</購入先名>
<購入先連絡先>000-0000-0000</購入先連絡先>
</購入先情報>
<仲介情報>
<仲介業者名>宮下物産</仲介業者名>
<営業担当者名>宮下</営業担当者名>
<仲介業者アドレス>miyashita@miyabussan.xx</仲介業者アドレス>
<仲介手数料>5</仲介手数料>
</仲介情報>
</注文>
......中略......
</注文データ>
いかがだろうか。新たに仲介情報が加わっても、XML DBならば<注文>要素の配下に<仲介情報>要素を追加するだけで済んでしまう。仲介情報が不要な<注文>要素はそのままでよいから、影響が及ぶのは仲介情報を必要とするノードにのみ限られる。また、物理的なデザインやスキーマの変更などを要求するわけでもないので、データの拡張・入れ替えに際しても、データベースの運用を一時的に停止する必要はない。データをロードしたその瞬間に、新しい情報はアクセスコントロールの対象となるのだ。
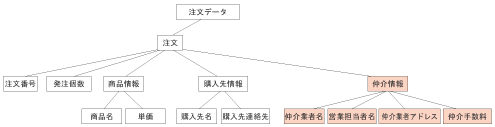
図5 XMLによるスキーマ変更
<注文>要素の配下に<仲介情報>要素(ピンク色の部分)を追加するだけでスキーマ変更は完了する。
独自のインデックス技術で"超"高速アクセスと低コストを実現するNeoCoreXMS
もっとも、すべてのXML DBが必ずしも、このようなXMLの柔軟性を十分に引き出せるわけではない。例えば、DTD(Document Type Definition)を前提としたXML DBでは、DTDを再構築したうえで対象データを再ロードしなければならないという手間は発生する。このような XML DBでも、RDBに比べれば変更の手間は削減されるが、データベースの入れ替えに相応の時間が要求されるのは否定できない。また、新しい構造でもってデータベース全体が即座に再構成されるわけではないので、例えば、インデックス化された高速なクエリなどを実行することはできない。構造変動が発生する都度、インデックスの再見直しを行わなければならないのは、なんらRDBのケースと変わらないのだ。
また、最新のRDB製品はXML対応を打ち出しているが、RDBのXML機能は基本的にDTD/XML Schemaを前提としているので、XMLデータを格納できるからといって、XMLの柔軟性を享受できるわけではない。
XML DB にはさまざまなコンセプトを持つ製品が存在するが、その中でも「NeoCore XML Management System(以下、NeoCoreXMS)」は、Well-Formedな(整形式)XMLを前提としたXML DBだ。つまり、構造の変動に対しても一切のスキーマ情報(DTD)を要求しない。また、フルインデックス方式を採用し、格納されたすべてのノードに対して自動的にインデックスを生成するから、インデックスの設計を開発者が意識する必要はない。しかも、構造変動に対して、常に高速なデータアクセスが望めるというわけだ。
フルインデックスと聞いて「インデックス領域の容量は大丈夫なのか」と心配される向きもあるかもしれない。たしかに一般的なインデックス方式だと、すべてのノードにインデックスを作成すれば、その容量は膨大にならざるを得ない。これに対してNeoCoreXMSでは、独自のDPP(Digital Pattern Processing)方式を採用している。XMLドキュメント中のすべてのノードは「ロケーションパス(階層構造)」とデータ本体で表現できる。 NeoCoreXMSでは、この「ロケーションパス+データ」を独自のアルゴリズムを用いて、「常に」64bitの固定長データ(これを「アイコン」と呼ぶ)に変換する。これによって、フルインデックスであるにも関らず、インデックスサイズはデータオリジナルの最大2.5倍以内に収めることができる。このDPP方式の採用によって、NeoCoreXMSではシステム構成にかかるコストを最小限に抑えながら、最大限の可用性を実現するのだ。
エンタープライズ機能を強化した最新バージョン、NeoCoreXMS 3.0
2004年4月にリリースされたNeoCoreXMSの最新バージョン「NeoCoreXMS 3.0」では、従来XML DBがRDBには及ばないとされてきたエンタープライズ系機能が大幅に強化された。
その中でも重要な機能強化は、「データベース領域の自動拡張」と「フラグメント領域の自動回復」である。データベースの内容は、運用の過程で常に変わっていくものだ。データは日々増えていくのが一般的であるし、更新/削除を伴うシステムではフラグメント(断片)も増えていく。従来はデータベース管理者が手作業でデータベースの領域拡張やデフラグ(断片化の解消)を行う必要があったわけだが、バージョン3.0からはこれらの作業が必要なくなった。 NeoCoreXMSが自律的にデータベース/フラグメント領域を監視し、データベース領域の拡張やフラグメント領域の回復を行うからだ。これらの新機能によって、NeoCoreXMSでは、日常的に発生しうる変動要素に対しても、限りなくメンテナンスフリーを実現できる。
そのほか、最新のNeoCoreXMSでは、データの整合性を保つためのトランザクション機能やユーザー管理を強化するなど、XML DB製品が業務システムでの活用にも十分耐え得るだけの機能を着実に実装している。もはやXML DBがエンタープライズ用途には向いていないと評される時代は過去のものとなった。2004年6月から NeoCoreXMSの無償版(一部制限を除き機能は同等)である「Xpriori」もリリースされているので、これを機に「柔軟なXML DB」の魅力を体験してみてはいかがだろうか。
- 1
- 2
▲このページのTOPへ






